` support.
```mermaid
flowchart TD
IN["LLM Output (Markdown)"] --> S1["Extract tables as placeholders"]
S1 --> S2["Extract code blocks as placeholders"]
S2 --> S3["Extract inline code as placeholders"]
S3 --> S4["Convert Markdown to HTML
(headers, bold, italic, links, lists)"]
S4 --> S5["Restore placeholders:
inline code as code tags
code blocks as pre tags
tables as pre (ASCII-aligned)"]
S5 --> S6["Chunk at 4000 chars
(split at paragraph > line > space)"]
S6 --> S7["Send as HTML
(fallback: plain text on error)"]
```
- **Table rendering**: Markdown tables are rendered as ASCII-aligned text inside `` tags (not `` to avoid "Copy" button). Cell content has inline markdown stripped (`**bold**`, `_italic_` markers removed).
- **CJK handling**: `displayWidth()` correctly counts CJK and emoji characters as 2-column width for proper table alignment.
---
## 6. Feishu/Lark
The Feishu/Lark channel connects via native HTTP with two transport modes.
### Transport Modes
```mermaid
flowchart TD
MODE{"Connection mode?"} -->|"ws (default)"| WS["WebSocket Client
Persistent connection
Auto-reconnect"]
MODE -->|"webhook"| WH["HTTP Webhook Server
Listens on configured port
Challenge verification"]
```
### Key Behaviors
- **Default domain**: Lark Global (`open.larksuite.com`). Configurable for Feishu China.
- **Streaming message cards**: Responses are delivered as interactive card messages with streaming updates, providing real-time output display. Updates are throttled at 100ms intervals with incrementing sequence numbers.
- **Media handling**: Supports image and file uploads/downloads with a default 30 MB limit.
- **Mention support**: Processes `@bot` mentions in group chats with mention text stripping.
- **Sender caching**: User names are cached with a 10-minute TTL to reduce API calls.
- **Deduplication**: Message IDs tracked via `sync.Map` to prevent processing duplicate events.
- **Pairing debounce**: 60-second debounce on pairing-related replies.
---
## 7. Discord
The Discord channel uses the `discordgo` library to connect via the Discord Gateway.
### Key Behaviors
- **Gateway intents**: Requests `GuildMessages`, `DirectMessages`, and `MessageContent` intents.
- **Message limit**: 2000-character limit per message, with automatic splitting for longer content.
- **Placeholder editing**: Sends an initial "Thinking..." message that gets edited with the actual response when complete.
- **Bot identity**: Fetches `@me` on startup to detect and ignore own messages.
---
## 8. WhatsApp
The WhatsApp channel communicates through an external WebSocket bridge (e.g., whatsapp-web.js based). GoClaw does not implement the WhatsApp protocol directly.
### Key Behaviors
- **Bridge connection**: Connects to a configurable `bridge_url` via WebSocket.
- **JSON format**: Messages are sent and received as JSON objects over the WebSocket connection.
- **Auto-reconnect**: If the initial connection fails, a background listen loop retries automatically.
- **DM and group support**: Both are supported through the bridge protocol.
---
## 9. Zalo
The Zalo channel connects to the Zalo OA Bot API.
### Key Behaviors
- **DM only**: No group support. Only direct messages are processed.
- **Text limit**: 2000-character maximum per message.
- **Long polling**: Uses long polling with a default 30-second timeout and 5-second backoff on errors.
- **Media**: Image support with a 5 MB default limit.
- **Default DM policy**: `"pairing"` (requires pairing code for new users).
- **Pairing debounce**: 60-second debounce to avoid flooding users with pairing instructions.
---
## 10. Pairing System
The pairing system provides a DM authentication flow for channels using the `pairing` DM policy.
### Flow
```mermaid
sequenceDiagram
participant U as New User
participant CH as Channel
participant PS as Pairing Service
participant O as Owner
U->>CH: First DM message
CH->>CH: Check DM policy = "pairing"
CH->>PS: Generate 8-char pairing code
PS-->>CH: Code (valid 60 min)
CH-->>U: "Reply with your pairing code from the admin"
Note over PS: Max 3 pending codes per account
O->>PS: Approve code via device.pair.approve
PS->>PS: Add sender to paired devices
U->>CH: Next DM message
CH->>PS: Check paired status
PS-->>CH: Paired (approved)
CH->>CH: Process message normally
```
### Code Specification
| Aspect | Value |
|--------|-------|
| Length | 8 characters |
| Alphabet | `ABCDEFGHJKLMNPQRSTUVWXYZ23456789` (excludes ambiguous: 0, O, 1, I, L) |
| TTL | 60 minutes |
| Max pending per account | 3 |
| Reply debounce | 60 seconds per sender |
---
## File Reference
| File | Purpose |
|------|---------|
| `internal/channels/channel.go` | Channel interface, BaseChannel, DMPolicy/GroupPolicy types, HandleMessage |
| `internal/channels/manager.go` | Manager: channel registration, StartAll, StopAll, outbound dispatch |
| `internal/channels/telegram/telegram.go` | Telegram channel: long polling, mention gating, typing indicators |
| `internal/channels/telegram/commands.go` | /stop, /stopall command handlers, menu registration |
| `internal/channels/telegram/format.go` | Markdown-to-Telegram-HTML pipeline, table rendering, CJK width |
| `internal/channels/telegram/format_test.go` | Tests for Telegram formatting pipeline |
| `internal/channels/feishu/feishu.go` | Feishu/Lark channel: WS/Webhook modes, card messages |
| `internal/channels/feishu/streaming.go` | Streaming message card updates |
| `internal/channels/feishu/media.go` | Media upload/download handling |
| `internal/channels/feishu/larkclient.go` | Native HTTP client for Lark API |
| `internal/channels/feishu/larkws.go` | WebSocket transport for Lark |
| `internal/channels/feishu/larkevents.go` | Event parsing and routing |
| `internal/channels/discord/discord.go` | Discord channel: gateway events, message editing |
| `internal/channels/whatsapp/whatsapp.go` | WhatsApp channel: external WS bridge |
| `internal/channels/zalo/zalo.go` | Zalo channel: OA Bot API, long polling, DM only |
| `internal/pairing/service.go` | Pairing service: code generation, approval, persistence |
| `cmd/gateway_consumer.go` | Message consumer: routing prefixes, handoff check, cancel interception |
---
# 06 - Store Layer and Data Model
The store layer abstracts all persistence behind Go interfaces, allowing the same core engine to run with file-based storage (standalone mode) or PostgreSQL (managed mode). Each store interface has independent implementations, and the system determines which backend to use based on configuration at startup.
---
## 1. Store Layer Routing
```mermaid
flowchart TD
START["Gateway Startup"] --> CHECK{"StoreConfig.IsManaged()?
(DSN + mode = managed)"}
CHECK -->|Yes| PG["PostgreSQL Backend"]
CHECK -->|No| FILE["File Backend"]
PG --> PG_STORES["PGSessionStore
PGAgentStore
PGProviderStore
PGCronStore
PGPairingStore
PGSkillStore
PGMemoryStore
PGTracingStore
PGMCPServerStore
PGCustomToolStore
PGChannelInstanceStore
PGConfigSecretsStore
PGAgentLinkStore
PGTeamStore"]
FILE --> FILE_STORES["FileSessionStore
FileMemoryStore (SQLite + FTS5)
FileCronStore
FilePairingStore
FileSkillStore
FileAgentStore (filesystem + SQLite)
ProviderStore = nil
TracingStore = nil
MCPServerStore = nil
CustomToolStore = nil
AgentLinks = nil
Teams = nil"]
```
---
## 2. Store Interface Map
The `Stores` struct is the top-level container holding all storage backends. In standalone mode, managed-only stores are `nil`.
| Interface | Standalone Implementation | Managed Implementation | Mode |
|-----------|--------------------------|------------------------|------|
| SessionStore | `FileSessionStore` via `sessions.Manager` | `PGSessionStore` | Both |
| MemoryStore | `FileMemoryStore` (SQLite + FTS5 + embeddings) | `PGMemoryStore` (tsvector + pgvector) | Both |
| CronStore | `FileCronStore` | `PGCronStore` | Both |
| PairingStore | `FilePairingStore` via `pairing.Service` | `PGPairingStore` | Both |
| SkillStore | `FileSkillStore` via `skills.Loader` | `PGSkillStore` | Both |
| AgentStore | `FileAgentStore` (filesystem + SQLite) | `PGAgentStore` | Both |
| ProviderStore | `nil` | `PGProviderStore` | Managed only |
| TracingStore | `nil` | `PGTracingStore` | Managed only |
| MCPServerStore | `nil` | `PGMCPServerStore` | Managed only |
| CustomToolStore | `nil` | `PGCustomToolStore` | Managed only |
| ChannelInstanceStore | `nil` | `PGChannelInstanceStore` | Managed only |
| ConfigSecretsStore | `nil` | `PGConfigSecretsStore` | Managed only |
| AgentLinkStore | `nil` | `PGAgentLinkStore` | Managed only |
| TeamStore | `nil` | `PGTeamStore` | Managed only |
### Standalone AgentStore (FileAgentStore)
In standalone mode, `FileAgentStore` provides per-user context files and profiles without PostgreSQL. It combines filesystem storage (agent-level files like SOUL.md) with SQLite (`~/.goclaw/data/agents.db`) for per-user data:
| Data | Storage |
|------|---------|
| Agent metadata | In-memory from `config.json` |
| Agent-level files (SOUL.md, IDENTITY.md, ...) | Filesystem at workspace root |
| Per-user files (USER.md, BOOTSTRAP.md) | SQLite `user_context_files` |
| User profiles | SQLite `user_profiles` |
| Group file writers | SQLite `group_file_writers` |
Agent UUIDs use UUID v5 (deterministic): `uuid.NewSHA1(namespace, "goclaw-standalone:{agentKey}")` -- stable across restarts without database sequences.
---
## 3. Session Caching
The session store uses an in-memory write-behind cache to minimize database I/O during the agent tool loop. All reads and writes happen in memory; data is flushed to the persistent backend only when `Save()` is called at the end of a run.
```mermaid
flowchart TD
subgraph "In-Memory Cache (map + mutex)"
ADD["AddMessage()"] --> CACHE["Session Cache"]
SET["SetSummary()"] --> CACHE
ACC["AccumulateTokens()"] --> CACHE
CACHE --> GET["GetHistory()"]
CACHE --> GETSM["GetSummary()"]
end
CACHE -->|"Save(key)"| DB[("PostgreSQL / JSON file")]
DB -->|"Cache miss via GetOrCreate"| CACHE
```
### Lifecycle
1. **GetOrCreate(key)**: Check cache; on miss, load from DB into cache; return session data.
2. **AddMessage/SetSummary/AccumulateTokens**: Update in-memory cache only (no DB write).
3. **Save(key)**: Snapshot data under read lock, flush to DB via UPDATE.
4. **Delete(key)**: Remove from both cache and DB. `List()` always reads directly from DB.
### Session Key Format
| Type | Format | Example |
|------|--------|---------|
| DM | `agent:{agentId}:{channel}:direct:{peerId}` | `agent:default:telegram:direct:386246614` |
| Group | `agent:{agentId}:{channel}:group:{groupId}` | `agent:default:telegram:group:-100123456` |
| Subagent | `agent:{agentId}:subagent:{label}` | `agent:default:subagent:my-task` |
| Cron | `agent:{agentId}:cron:{jobId}:run:{runId}` | `agent:default:cron:reminder:run:abc123` |
| Main | `agent:{agentId}:{mainKey}` | `agent:default:main` |
### File-Based Persistence (Standalone)
- Startup: `loadAll()` reads all `.json` files into memory
- Save: temp file + rename (atomic write, prevents corruption on crash)
- Filename: session key with `:` replaced by `_`, plus `.json` extension
---
## 4. Agent Access Control
In managed mode, agent access is checked via a 4-step pipeline.
```mermaid
flowchart TD
REQ["CanAccess(agentID, userID)"] --> S1{"Agent exists?"}
S1 -->|No| DENY["Deny"]
S1 -->|Yes| S2{"is_default = true?"}
S2 -->|Yes| ALLOW["Allow
(role = owner if owner,
user otherwise)"]
S2 -->|No| S3{"owner_id = userID?"}
S3 -->|Yes| ALLOW_OWNER["Allow (role = owner)"]
S3 -->|No| S4{"Record in agent_shares?"}
S4 -->|Yes| ALLOW_SHARE["Allow (role from share)"]
S4 -->|No| DENY
```
The `agent_shares` table stores `UNIQUE(agent_id, user_id)` with roles: `user`, `admin`, `operator`.
`ListAccessible(userID)` queries: `owner_id = ? OR is_default = true OR id IN (SELECT agent_id FROM agent_shares WHERE user_id = ?)`.
---
## 5. API Key Encryption
API keys in the `llm_providers` and `mcp_servers` tables are encrypted with AES-256-GCM before storage.
```mermaid
flowchart LR
subgraph "Storing a key"
PLAIN["Plaintext API key"] --> ENC["AES-256-GCM encrypt"]
ENC --> DB["DB: 'aes-gcm:' + base64(nonce + ciphertext + tag)"]
end
subgraph "Loading a key"
DB2["DB value"] --> CHECK{"Has 'aes-gcm:' prefix?"}
CHECK -->|Yes| DEC["AES-256-GCM decrypt"]
CHECK -->|No| RAW["Return as-is
(backward compatibility)"]
DEC --> USE["Plaintext key"]
RAW --> USE
end
```
`GOCLAW_ENCRYPTION_KEY` accepts three formats:
- **Hex**: 64 characters (decoded to 32 bytes)
- **Base64**: 44 characters (decoded to 32 bytes)
- **Raw**: 32 characters (32 bytes direct)
---
## 6. Hybrid Memory Search
Memory search combines full-text search (FTS) and vector similarity in a weighted merge.
```mermaid
flowchart TD
QUERY["Search(query, agentID, userID)"] --> PAR
subgraph PAR["Parallel Search"]
FTS["FTS Search
tsvector + plainto_tsquery
Weight: 0.3"]
VEC["Vector Search
pgvector cosine distance
Weight: 0.7"]
end
FTS --> MERGE["hybridMerge()"]
VEC --> MERGE
MERGE --> BOOST["Per-user scope: 1.2x boost
Dedup: user copy wins over global"]
BOOST --> FILTER["Min score filter
+ max results limit"]
FILTER --> RESULT["Sorted results"]
```
### Merge Rules
1. Normalize FTS scores to [0, 1] (divide by highest score)
2. Vector scores already in [0, 1] (cosine similarity)
3. Combined score: `vec_score * 0.7 + fts_score * 0.3` for chunks found by both
4. When only one channel returns results, its weight auto-adjusts to 1.0
5. Per-user results receive a 1.2x boost
6. Deduplication: if a chunk exists in both global and per-user scope, the per-user version wins
### Fallback
When FTS returns no results (e.g., cross-language queries), a `likeSearch()` fallback runs ILIKE queries using up to 5 keywords (minimum 3 characters each), scoped to the agent's index.
### Standalone vs Managed
| Aspect | Standalone | Managed |
|--------|-----------|---------|
| FTS engine | SQLite FTS5 | PostgreSQL tsvector |
| Vector | Embedding cache | pgvector extension |
| Search function | `plainto_tsquery('simple', ...)` | Same |
| Distance operator | N/A | `<=>` (cosine) |
---
## 7. Context Files Routing
Context files are stored in two tables and routed based on agent type.
### Tables
| Table | Scope | Unique Key |
|-------|-------|------------|
| `agent_context_files` | Agent-level | `(agent_id, file_name)` |
| `user_context_files` | Per-user | `(agent_id, user_id, file_name)` |
### Routing by Agent Type
| Agent Type | Agent-Level Files | Per-User Files |
|------------|-------------------|----------------|
| `open` | Template fallback only | All 7 files (SOUL, IDENTITY, AGENTS, TOOLS, HEARTBEAT, BOOTSTRAP, USER) |
| `predefined` | 6 files (SOUL, IDENTITY, AGENTS, TOOLS, HEARTBEAT, BOOTSTRAP) | Only USER.md |
The `ContextFileInterceptor` checks agent type from context and routes read/write operations accordingly. For open agents, per-user files take priority with agent-level as fallback.
---
## 8. MCP Server Store
The MCP server store manages external tool server configurations and access grants.
### Tables
| Table | Purpose |
|-------|---------|
| `mcp_servers` | Server configurations (name, transport, command/URL, encrypted API key) |
| `mcp_agent_grants` | Per-agent access grants with tool allow/deny lists |
| `mcp_user_grants` | Per-user access grants with tool allow/deny lists |
| `mcp_access_requests` | Pending/approved/rejected access requests |
### Transport Types
| Transport | Fields Used |
|-----------|-------------|
| `stdio` | `command`, `args` (JSONB), `env` (JSONB) |
| `sse` | `url`, `headers` (JSONB) |
| `streamable-http` | `url`, `headers` (JSONB) |
`ListAccessible(agentID, userID)` returns all MCP servers the given agent+user combination can access, with effective tool allow/deny lists merged from both agent and user grants.
---
## 9. Custom Tool Store
Dynamic tool definitions stored in PostgreSQL. Each tool defines a shell command template that the LLM can invoke at runtime.
### Table: `custom_tools`
| Column | Type | Description |
|--------|------|-------------|
| `id` | UUID v7 | Primary key |
| `name` | VARCHAR | Unique tool name |
| `description` | TEXT | Tool description for the LLM |
| `parameters` | JSONB | JSON Schema for tool arguments |
| `command` | TEXT | Shell command template with `{{.key}}` placeholders |
| `working_dir` | VARCHAR | Optional working directory |
| `timeout_seconds` | INT | Execution timeout (default 60) |
| `env` | BYTEA | Encrypted environment variables (AES-256-GCM) |
| `agent_id` | UUID | `NULL` = global tool, UUID = per-agent tool |
| `enabled` | BOOLEAN | Soft enable/disable |
| `created_by` | VARCHAR | Audit trail |
**Scoping**: Global tools (`agent_id IS NULL`) are loaded at startup into the global registry. Per-agent tools are loaded on-demand when the agent is resolved, using a cloned registry to avoid polluting the global one.
---
## 10. Agent Link Store
The agent link store manages inter-agent delegation permissions -- directed edges that control which agents can delegate to which others.
### Table: `agent_links`
| Column | Type | Description |
|--------|------|-------------|
| `id` | UUID v7 | Primary key |
| `source_agent_id` | UUID | Agent that can delegate (FK → agents) |
| `target_agent_id` | UUID | Agent being delegated to (FK → agents) |
| `direction` | VARCHAR(20) | `outbound` (A→B only), `bidirectional` (A↔B) |
| `team_id` | UUID | Non-nil = auto-created by team setup (FK → agent_teams, SET NULL on delete) |
| `description` | TEXT | Link description |
| `max_concurrent` | INT | Per-link concurrency cap (default 3) |
| `settings` | JSONB | Per-user deny/allow lists for fine-grained access control |
| `status` | VARCHAR(20) | `active` or `disabled` |
| `created_by` | VARCHAR | Audit trail |
**Constraints**: `UNIQUE(source_agent_id, target_agent_id)`, `CHECK (source_agent_id != target_agent_id)`
### Agent Search Columns (migration 000002)
The `agents` table gains three columns for agent discovery during delegation:
| Column | Type | Purpose |
|--------|------|---------|
| `frontmatter` | TEXT | Short expertise summary (distinct from `other_config.description` which is the summoning prompt) |
| `tsv` | TSVECTOR | Auto-generated from `display_name + frontmatter`, GIN-indexed |
| `embedding` | VECTOR(1536) | For cosine similarity search, HNSW-indexed |
### AgentLinkStore Interface (12 methods)
- **CRUD**: `CreateLink`, `DeleteLink`, `UpdateLink`, `GetLink`
- **Queries**: `ListLinksFrom(agentID)`, `ListLinksTo(agentID)`
- **Permission**: `CanDelegate(from, to)`, `GetLinkBetween(from, to)` (returns full link with Settings for per-user checks)
- **Discovery**: `DelegateTargets(agentID)` (all targets with joined agent_key + display_name for DELEGATION.md), `SearchDelegateTargets` (FTS), `SearchDelegateTargetsByEmbedding` (vector cosine)
### Table: `delegation_history`
| Column | Type | Description |
|--------|------|-------------|
| `id` | UUID v7 | Primary key |
| `source_agent_id` | UUID | Delegating agent |
| `target_agent_id` | UUID | Target agent |
| `team_id` | UUID | Team context (nullable) |
| `team_task_id` | UUID | Related team task (nullable) |
| `user_id` | VARCHAR | User who triggered the delegation |
| `task` | TEXT | Task description sent to target |
| `mode` | VARCHAR(10) | `sync` or `async` |
| `status` | VARCHAR(20) | `completed`, `failed`, `cancelled` |
| `result` | TEXT | Target agent's response |
| `error` | TEXT | Error message on failure |
| `iterations` | INT | Number of LLM iterations |
| `trace_id` | UUID | Linked trace for observability |
| `duration_ms` | INT | Wall-clock duration |
| `completed_at` | TIMESTAMPTZ | Completion timestamp |
Every sync and async delegation is persisted here automatically via `SaveDelegationHistory()`. Results are truncated for WS transport (500 runes for list, 8000 runes for detail).
---
## 11. Team Store
The team store manages collaborative multi-agent teams with a shared task board, peer-to-peer mailbox, and handoff routing.
### Tables
| Table | Purpose | Key Columns |
|-------|---------|-------------|
| `agent_teams` | Team definitions | `name`, `lead_agent_id` (FK → agents), `status`, `settings` (JSONB) |
| `agent_team_members` | Team membership | PK `(team_id, agent_id)`, `role` (lead/member) |
| `team_tasks` | Shared task board | `subject`, `status` (pending/in_progress/completed/blocked), `owner_agent_id`, `blocked_by` (UUID[]), `priority`, `result`, `tsv` (FTS) |
| `team_messages` | Peer-to-peer mailbox | `from_agent_id`, `to_agent_id` (NULL = broadcast), `content`, `message_type` (chat/broadcast), `read` |
| `handoff_routes` | Active routing overrides | UNIQUE `(channel, chat_id)`, `from_agent_key`, `to_agent_key`, `reason` |
### TeamStore Interface (22 methods)
**Team CRUD**: `CreateTeam`, `GetTeam`, `DeleteTeam`, `ListTeams`
**Members**: `AddMember`, `RemoveMember`, `ListMembers`, `GetTeamForAgent` (find team by agent)
**Tasks**: `CreateTask`, `UpdateTask`, `ListTasks` (orderBy: priority/newest, statusFilter: active/completed/all), `GetTask`, `SearchTasks` (FTS on subject+description), `ClaimTask`, `CompleteTask`
**Delegation History**: `SaveDelegationHistory`, `ListDelegationHistory` (with filter opts), `GetDelegationHistory`
**Handoff Routes**: `SetHandoffRoute`, `GetHandoffRoute`, `ClearHandoffRoute`
**Messages**: `SendMessage`, `GetUnread`, `MarkRead`
### Atomic Task Claiming
Two agents grabbing the same task is prevented at the database level:
```sql
UPDATE team_tasks
SET status = 'in_progress', owner_agent_id = $1
WHERE id = $2 AND status = 'pending' AND owner_agent_id IS NULL
```
One row updated = claimed. Zero rows = someone else got it. Row-level locking, no distributed mutex needed.
### Task Dependencies
Tasks can declare `blocked_by` (UUID array) pointing to prerequisite tasks. When a task is completed via `CompleteTask`, all dependent tasks whose blockers are now all completed are automatically unblocked (status transitions from `blocked` to `pending`).
---
## 12. Database Schema
All tables use UUID v7 (time-ordered) as primary keys via `GenNewID()`.
```mermaid
flowchart TD
subgraph Providers
LP["llm_providers"] --> LM["llm_models"]
end
subgraph Agents
AG["agents"] --> AS["agent_shares"]
AG --> ACF["agent_context_files"]
AG --> UCF["user_context_files"]
AG --> UAP["user_agent_profiles"]
end
subgraph "Agent Links"
AG --> AL["agent_links"]
AL --> DH["delegation_history"]
end
subgraph Teams
AT["agent_teams"] --> ATM["agent_team_members"]
AT --> TT["team_tasks"]
AT --> TM["team_messages"]
end
subgraph Handoff
HR["handoff_routes"]
end
subgraph Sessions
SE["sessions"]
end
subgraph Memory
MD["memory_documents"] --> MC["memory_chunks"]
end
subgraph Cron
CJ["cron_jobs"] --> CRL["cron_run_logs"]
end
subgraph Pairing
PR["pairing_requests"]
PD["paired_devices"]
end
subgraph Skills
SK["skills"] --> SAG["skill_agent_grants"]
SK --> SUG["skill_user_grants"]
end
subgraph Tracing
TR["traces"] --> SP["spans"]
end
subgraph MCP
MS["mcp_servers"] --> MAG["mcp_agent_grants"]
MS --> MUG["mcp_user_grants"]
MS --> MAR["mcp_access_requests"]
end
subgraph "Custom Tools"
CT["custom_tools"]
end
```
### Key Tables
| Table | Purpose | Key Columns |
|-------|---------|-------------|
| `agents` | Agent definitions | `agent_key` (UNIQUE), `owner_id`, `agent_type` (open/predefined), `is_default`, `frontmatter`, `tsv`, `embedding`, soft delete via `deleted_at` |
| `agent_shares` | Agent RBAC sharing | UNIQUE(agent_id, user_id), `role` (user/admin/operator) |
| `agent_context_files` | Agent-level context | UNIQUE(agent_id, file_name) |
| `user_context_files` | Per-user context | UNIQUE(agent_id, user_id, file_name) |
| `user_agent_profiles` | User tracking | `first_seen_at`, `last_seen_at`, `workspace` |
| `agent_links` | Inter-agent delegation permissions | UNIQUE(source, target), `direction`, `max_concurrent`, `settings` (JSONB) |
| `agent_teams` | Team definitions | `name`, `lead_agent_id`, `status`, `settings` (JSONB) |
| `agent_team_members` | Team membership | PK(team_id, agent_id), `role` (lead/member) |
| `team_tasks` | Shared task board | `subject`, `status`, `owner_agent_id`, `blocked_by` (UUID[]), `tsv` (FTS) |
| `team_messages` | Peer-to-peer mailbox | `from_agent_id`, `to_agent_id`, `message_type`, `read` |
| `delegation_history` | Persisted delegation records | `source_agent_id`, `target_agent_id`, `mode`, `status`, `result`, `trace_id` |
| `handoff_routes` | Active routing overrides | UNIQUE(channel, chat_id), `from_agent_key`, `to_agent_key` |
| `sessions` | Conversation history | `session_key` (UNIQUE), `messages` (JSONB), `summary`, token counts |
| `memory_documents` | Memory docs | UNIQUE(agent_id, COALESCE(user_id, ''), path) |
| `memory_chunks` | Chunked + embedded text | `embedding` (VECTOR), `tsv` (TSVECTOR) |
| `llm_providers` | Provider configuration | `api_key` (AES-256-GCM encrypted) |
| `traces` | LLM call traces | `agent_id`, `user_id`, `status`, `parent_trace_id`, aggregated token counts |
| `spans` | Individual operations | `span_type` (llm_call, tool_call, agent, embedding), `parent_span_id` |
| `skills` | Skill definitions | Content, metadata, grants |
| `cron_jobs` | Scheduled tasks | `schedule_kind` (at/every/cron), `payload` (JSONB) |
| `mcp_servers` | MCP server configs | `transport`, `api_key` (encrypted), `tool_prefix` |
| `custom_tools` | Dynamic tool definitions | `command` (template), `agent_id` (NULL = global), `env` (encrypted) |
### Migrations
| Migration | Purpose |
|-----------|---------|
| `000001_init_schema` | Core tables (agents, sessions, providers, memory, cron, pairing, skills, traces, MCP, custom tools) |
| `000002_agent_links` | `agent_links` table + `frontmatter`, `tsv`, `embedding` on agents + `parent_trace_id` on traces |
| `000003_agent_teams` | `agent_teams`, `agent_team_members`, `team_tasks`, `team_messages` + `team_id` on agent_links |
| `000004_teams_v2` | FTS on `team_tasks` (tsv column) + `delegation_history` table |
| `000005_phase4` | `handoff_routes` table |
### Required PostgreSQL Extensions
- **pgvector**: Vector similarity search for memory embeddings
- **pgcrypto**: UUID generation functions
---
## 13. Context Propagation
Metadata flows through `context.Context` instead of mutable state, ensuring thread safety across concurrent agent runs.
```mermaid
flowchart TD
HANDLER["HTTP/WS Handler"] -->|"store.WithUserID(ctx)
store.WithAgentID(ctx)
store.WithAgentType(ctx)"| LOOP["Agent Loop"]
LOOP -->|"tools.WithToolChannel(ctx)
tools.WithToolChatID(ctx)
tools.WithToolPeerKind(ctx)"| TOOL["Tool Execute(ctx)"]
TOOL -->|"store.UserIDFromContext(ctx)
store.AgentIDFromContext(ctx)
tools.ToolChannelFromCtx(ctx)"| LOGIC["Domain Logic"]
```
### Store Context Keys
| Key | Type | Purpose |
|-----|------|---------|
| `goclaw_user_id` | string | External user ID (e.g., Telegram user ID) |
| `goclaw_agent_id` | uuid.UUID | Agent UUID (managed mode) |
| `goclaw_agent_type` | string | Agent type: `"open"` or `"predefined"` |
| `goclaw_sender_id` | string | Original individual sender ID (in group chats, `user_id` is group-scoped but `sender_id` preserves the actual person) |
### Tool Context Keys
| Key | Purpose |
|-----|---------|
| `tool_channel` | Current channel (telegram, discord, etc.) |
| `tool_chat_id` | Chat/conversation identifier |
| `tool_peer_kind` | Peer type: `"direct"` or `"group"` |
| `tool_sandbox_key` | Docker sandbox scope key |
| `tool_async_cb` | Callback for async tool execution |
| `tool_workspace` | Per-user workspace directory (injected by agent loop, read by filesystem/shell tools) |
---
## 14. Key PostgreSQL Patterns
### Database Driver
All PG stores use `database/sql` with the `pgx/v5/stdlib` driver. No ORM is used -- all queries are raw SQL with positional parameters (`$1`, `$2`, ...).
### Nullable Columns
Nullable columns are handled via Go pointers: `*string`, `*int`, `*time.Time`, `*uuid.UUID`. Helper functions `nilStr()`, `nilInt()`, `nilUUID()`, `nilTime()` convert zero values to `nil` for clean SQL insertion.
### Dynamic Updates
`execMapUpdate()` builds UPDATE statements dynamically from a `map[string]any` of column-value pairs. This avoids writing a separate UPDATE query for every combination of updatable fields.
### Upsert Pattern
All "create or update" operations use `INSERT ... ON CONFLICT DO UPDATE`, ensuring idempotency:
| Operation | Conflict Key |
|-----------|-------------|
| `SetAgentContextFile` | `(agent_id, file_name)` |
| `SetUserContextFile` | `(agent_id, user_id, file_name)` |
| `ShareAgent` | `(agent_id, user_id)` |
| `PutDocument` (memory) | `(agent_id, COALESCE(user_id, ''), path)` |
| `GrantToAgent` (skill) | `(skill_id, agent_id)` |
### User Profile Detection
`GetOrCreateUserProfile` uses the PostgreSQL `xmax` trick:
- `xmax = 0` after RETURNING means a real INSERT occurred (new user) -- triggers context file seeding
- `xmax != 0` means an UPDATE on conflict (existing user) -- no seeding needed
### Batch Span Insert
`BatchCreateSpans` inserts spans in batches of 100. If a batch fails, it falls back to inserting each span individually to prevent data loss.
---
## File Reference
| File | Purpose |
|------|---------|
| `internal/store/stores.go` | `Stores` container struct (all 14 store interfaces) |
| `internal/store/types.go` | `BaseModel`, `StoreConfig`, `GenNewID()` |
| `internal/store/context.go` | Context propagation: `WithUserID`, `WithAgentID`, `WithAgentType`, `WithSenderID` |
| `internal/store/session_store.go` | `SessionStore` interface, `SessionData`, `SessionInfo` |
| `internal/store/memory_store.go` | `MemoryStore` interface, `MemorySearchResult`, `EmbeddingProvider` |
| `internal/store/skill_store.go` | `SkillStore` interface |
| `internal/store/agent_store.go` | `AgentStore` interface |
| `internal/store/agent_link_store.go` | `AgentLinkStore` interface, `AgentLinkData`, link constants |
| `internal/store/team_store.go` | `TeamStore` interface, `TeamData`, `TeamTaskData`, `DelegationHistoryData`, `HandoffRouteData`, `TeamMessageData` |
| `internal/store/provider_store.go` | `ProviderStore` interface |
| `internal/store/tracing_store.go` | `TracingStore` interface, `TraceData`, `SpanData` |
| `internal/store/mcp_store.go` | `MCPServerStore` interface, grant types, access request types |
| `internal/store/channel_instance_store.go` | `ChannelInstanceStore` interface |
| `internal/store/config_secrets_store.go` | `ConfigSecretsStore` interface |
| `internal/store/pairing_store.go` | `PairingStore` interface |
| `internal/store/cron_store.go` | `CronStore` interface |
| `internal/store/custom_tool_store.go` | `CustomToolStore` interface |
| `internal/store/file/agents.go` | `FileAgentStore`: filesystem + SQLite backend for standalone mode |
| `internal/store/pg/factory.go` | PG store factory: creates all PG store instances from a connection pool |
| `internal/store/pg/sessions.go` | `PGSessionStore`: session cache, Save, GetOrCreate |
| `internal/store/pg/agents.go` | `PGAgentStore`: CRUD, soft delete, access control |
| `internal/store/pg/agents_context.go` | Agent and user context file operations |
| `internal/store/pg/agent_links.go` | `PGAgentLinkStore`: link CRUD, permissions, FTS + vector search |
| `internal/store/pg/teams.go` | `PGTeamStore`: teams, tasks (atomic claim), messages, delegation history, handoff routes |
| `internal/store/pg/memory_docs.go` | `PGMemoryStore`: document CRUD, indexing, chunking |
| `internal/store/pg/memory_search.go` | Hybrid search: FTS, vector, ILIKE fallback, merge |
| `internal/store/pg/skills.go` | `PGSkillStore`: skill CRUD and grants |
| `internal/store/pg/skills_grants.go` | Skill agent and user grants |
| `internal/store/pg/mcp_servers.go` | `PGMCPServerStore`: server CRUD, grants, access requests |
| `internal/store/pg/channel_instances.go` | `PGChannelInstanceStore`: channel instance CRUD |
| `internal/store/pg/config_secrets.go` | `PGConfigSecretsStore`: encrypted config secrets |
| `internal/store/pg/custom_tools.go` | `PGCustomToolStore`: custom tool CRUD with encrypted env |
| `internal/store/pg/providers.go` | `PGProviderStore`: provider CRUD with encrypted keys |
| `internal/store/pg/tracing.go` | `PGTracingStore`: traces and spans with batch insert |
| `internal/store/pg/pool.go` | Connection pool management |
| `internal/store/pg/helpers.go` | Nullable helpers, JSON helpers, `execMapUpdate()` |
| `internal/store/validate.go` | Input validation utilities |
| `internal/tools/context_keys.go` | Tool context keys including `WithToolWorkspace` |
---
# 07 - Bootstrap, Skills & Memory
Three foundational systems that shape each agent's personality (Bootstrap), knowledge (Skills), and long-term recall (Memory).
### Responsibilities
- Bootstrap: load context files, truncate to fit context window, seed templates for new users
- Skills: 5-tier resolution hierarchy, BM25 search, hot-reload via fsnotify
- Memory: chunking, hybrid search (FTS + vector), memory flush before compaction
- System Prompt: build 15+ sections in a fixed order with two modes (full and minimal)
---
## 1. Bootstrap Files -- 7 Template Files
Markdown files loaded at agent initialization and embedded into the system prompt. MEMORY.md is NOT a bootstrap template file; it is a separate memory document loaded independently.
| # | File | Role | Full Session | Subagent/Cron |
|---|------|------|:---:|:---:|
| 1 | AGENTS.md | Operating instructions, memory rules, safety guidelines | Yes | Yes |
| 2 | SOUL.md | Persona, tone of voice, boundaries | Yes | No |
| 3 | TOOLS.md | Local tool notes (camera, SSH, TTS, etc.) | Yes | Yes |
| 4 | IDENTITY.md | Agent name, creature, vibe, emoji | Yes | No |
| 5 | USER.md | User profile (name, timezone, preferences) | Yes | No |
| 6 | HEARTBEAT.md | Periodic check task list | Yes | No |
| 7 | BOOTSTRAP.md | First-run ritual (deleted after completion) | Yes | No |
Subagent and cron sessions load only AGENTS.md + TOOLS.md (the `minimalAllowlist`).
---
## 2. Truncation Pipeline
Bootstrap content can exceed the context window budget. A 4-step pipeline truncates files to fit, matching the behavior of the TypeScript implementation.
```mermaid
flowchart TD
IN["Ordered list of bootstrap files"] --> S1["Step 1: Skip empty or missing files"]
S1 --> S2["Step 2: Per-file truncation
If > MaxCharsPerFile (20K):
Keep 70% head + 20% tail
Insert [...truncated] marker"]
S2 --> S3["Step 3: Clamp to remaining
total budget (starts at 24K)"]
S3 --> S4{"Step 4: Remaining budget < 64?"}
S4 -->|Yes| STOP["Stop processing further files"]
S4 -->|No| NEXT["Continue to next file"]
```
### Truncation Defaults
| Parameter | Value |
|-----------|-------|
| MaxCharsPerFile | 20,000 |
| TotalMaxChars | 24,000 |
| MinFileBudget | 64 |
| HeadRatio | 70% |
| TailRatio | 20% |
When a file is truncated, a marker is inserted between the head and tail sections:
`[...truncated, read SOUL.md for full content...]`
---
## 3. Seeding -- Template Creation
Templates are embedded in the binary via Go `embed` (directory: `internal/bootstrap/templates/`). Seeding automatically creates default files for new workspaces or new users.
```mermaid
flowchart TD
subgraph "Standalone Mode"
SA["EnsureWorkspaceFiles()"] --> SA1["Iterate over embedded templates"]
SA1 --> SA2{"File already exists?
(O_EXCL atomic check)"}
SA2 -->|Yes| SKIP1["Skip"]
SA2 -->|No| CREATE1["Create template file on disk"]
end
subgraph "Standalone Mode -- Per-User (FileAgentStore)"
SU["SeedUserFiles()"] --> SU1{"Agent type?"}
SU1 -->|open| SU_OPEN["Seed all 7 files to SQLite"]
SU1 -->|predefined| SU_PRED["Seed USER.md + BOOTSTRAP.md to SQLite"]
SU_OPEN --> SU_CHK{"Row already exists?"}
SU_PRED --> SU_CHK
SU_CHK -->|Yes| SKIP_SU["Skip"]
SU_CHK -->|No| SU_WRITE["INSERT into user_context_files"]
end
subgraph "Managed Mode -- Agent Level"
SB["SeedToStore()"] --> SB1{"Agent type = open?"}
SB1 -->|Yes| SKIP_AGENT["Skip (open agents use per-user only)"]
SB1 -->|No| SB2["Seed 6 files to agent_context_files
(all except BOOTSTRAP.md)"]
SB2 --> SB3{"File already has content?"}
SB3 -->|Yes| SKIP2["Skip"]
SB3 -->|No| WRITE2["Write embedded template"]
end
subgraph "Managed Mode -- Per-User"
MC["SeedUserFiles()"] --> MC1{"Agent type?"}
MC1 -->|open| OPEN["Seed all 7 files to user_context_files"]
MC1 -->|predefined| PRED["Seed USER.md + BOOTSTRAP.md to user_context_files"]
OPEN --> CHECK{"File already has content?"}
PRED --> CHECK
CHECK -->|Yes| SKIP3["Skip -- never overwrite"]
CHECK -->|No| WRITE3["Write embedded template"]
end
```
`SeedUserFiles()` is idempotent -- safe to call multiple times without overwriting personalized content.
### Standalone UUID Generation
Standalone agents are defined in `config.json` without database-generated UUIDs. `FileAgentStore` uses UUID v5 (`uuid.NewSHA1(namespace, "goclaw-standalone:{agentKey}")`) to produce deterministic IDs from agent keys. This ensures SQLite rows for per-user files survive process restarts without coordination.
### Predefined Agent Bootstrap
Both standalone and managed mode now seed `BOOTSTRAP.md` for predefined agents (per-user). On first chat, the agent runs the bootstrap ritual (learn name, preferences), then writes an empty `BOOTSTRAP.md` which triggers deletion. The empty-write deletion is ordered *before* the predefined write-block in `ContextFileInterceptor` to prevent an infinite bootstrap loop.
---
## 4. Agent Type Routing
Two agent types determine which context files live at the agent level versus the per-user level. Agent types are now available in both managed and standalone modes.
| Agent Type | Agent-Level Files | Per-User Files |
|------------|-------------------|----------------|
| `open` | None | All 7 files (AGENTS, SOUL, TOOLS, IDENTITY, USER, HEARTBEAT, BOOTSTRAP) |
| `predefined` | 6 files (shared across all users) | USER.md + BOOTSTRAP.md |
For `open` agents, each user gets their own full set of context files. When a file is read, the system checks the per-user copy first and falls back to the agent-level copy if not found. For `predefined` agents, all users share the same agent-level files except USER.md (personalized) and BOOTSTRAP.md (per-user first-run ritual, deleted after completion).
| Mode | Agent Type Source | Per-User Storage |
|------|------------------|-----------------|
| Managed | `agents` PostgreSQL table | `user_context_files` table |
| Standalone | `config.json` agent entries | SQLite via `FileAgentStore` |
---
## 5. System Prompt -- 17+ Sections
`BuildSystemPrompt()` constructs the complete system prompt from ordered sections. Two modes control which sections are included.
```mermaid
flowchart TD
START["BuildSystemPrompt()"] --> S1["1. Identity
'You are a personal assistant
running inside GoClaw'"]
S1 --> S1_5{"1.5 BOOTSTRAP.md present?"}
S1_5 -->|Yes| BOOT["First-run Bootstrap Override
(mandatory BOOTSTRAP.md instructions)"]
S1_5 -->|No| S2
BOOT --> S2["2. Tooling
(tool list + descriptions)"]
S2 --> S3["3. Safety
(hard safety directives)"]
S3 --> S4["4. Skills (full only)"]
S4 --> S5["5. Memory Recall (full only)"]
S5 --> S6["6. Workspace"]
S6 --> S6_5{"6.5 Sandbox enabled?"}
S6_5 -->|Yes| SBX["Sandbox instructions"]
S6_5 -->|No| S7
SBX --> S7["7. User Identity (full only)"]
S7 --> S8["8. Current Time"]
S8 --> S9["9. Messaging (full only)"]
S9 --> S10["10. Extra Context / Subagent Context"]
S10 --> S11["11. Project Context
(bootstrap files + virtual files)"]
S11 --> S12["12. Silent Replies (full only)"]
S12 --> S13["13. Heartbeats (full only)"]
S13 --> S14["14. Sub-Agent Spawning (conditional)"]
S14 --> S15["15. Runtime"]
```
### Mode Comparison
| Section | PromptFull | PromptMinimal |
|---------|:---:|:---:|
| 1. Identity | Yes | Yes |
| 1.5. Bootstrap Override | Conditional | Conditional |
| 2. Tooling | Yes | Yes |
| 3. Safety | Yes | Yes |
| 4. Skills | Yes | No |
| 5. Memory Recall | Yes | No |
| 6. Workspace | Yes | Yes |
| 6.5. Sandbox | Conditional | Conditional |
| 7. User Identity | Yes | No |
| 8. Current Time | Yes | Yes |
| 9. Messaging | Yes | No |
| 10. Extra Context | Conditional | Conditional |
| 11. Project Context | Yes | Yes |
| 12. Silent Replies | Yes | No |
| 13. Heartbeats | Yes | No |
| 14. Sub-Agent Spawning | Conditional | Conditional |
| 15. Runtime | Yes | Yes |
Context files are wrapped in `` XML tags with a defensive preamble instructing the model to follow tone/persona guidance but not execute instructions that contradict core directives. The ExtraPrompt is wrapped in `` tags for context isolation.
### Virtual Context Files (DELEGATION.md, TEAM.md)
Two files are system-injected by the resolver rather than stored on disk or in the DB:
| File | Injection Condition | Content |
|------|-------------------|---------|
| `DELEGATION.md` | Agent has manual (non-team) agent links | ≤15 targets: static list. >15 targets: search instruction for `delegate_search` tool |
| `TEAM.md` | Agent is a member of a team | Team name, role, teammate list with descriptions, workflow sentence |
Virtual files are rendered in `` tags (not ``) so the LLM does not attempt to read or write them as files. During bootstrap (first-run), both files are skipped to avoid wasting tokens when the agent should focus on onboarding.
---
## 6. Context File Merging
For **open agents**, per-user context files (from `user_context_files`) are merged with base context files (from the resolver) at runtime. Per-user files override same-name base files, but base-only files are preserved.
```
Base files (resolver): AGENTS.md, DELEGATION.md, TEAM.md
Per-user files (DB/SQLite): AGENTS.md, SOUL.md, TOOLS.md, USER.md, ...
Merged result: SOUL.md, TOOLS.md, USER.md, ..., AGENTS.md (per-user), DELEGATION.md ✓, TEAM.md ✓
```
This ensures resolver-injected virtual files (`DELEGATION.md`, `TEAM.md`) survive alongside per-user customizations. The merge logic lives in `internal/agent/loop_history.go`.
---
## 7. Agent Summoning (Managed Mode)
Creating a predefined agent requires 5 context files (SOUL.md, IDENTITY.md, AGENTS.md, TOOLS.md, HEARTBEAT.md) with specific formatting conventions. Agent summoning generates all 5 files from a natural language description in a single LLM call.
```mermaid
flowchart TD
USER["User: 'sarcastic Rust reviewer'"] --> API["Backend (POST /v1/agents/{id}/summon)"]
API -->|"status: summoning"| DB["Database"]
API --> LLM["LLM call with structured XML prompt"]
LLM --> PARSE["Parse XML output into 5 files"]
PARSE --> STORE["Write files to agent_context_files"]
STORE -->|"status: active"| READY["Agent ready"]
LLM -.->|"WS events"| UI["Dashboard modal with progress"]
```
The LLM outputs structured XML with each file in a tagged block. Parsing is done server-side in `internal/http/summoner.go`. If the LLM fails (timeout, bad XML, no provider), the agent falls back to embedded template files and goes active anyway. The user can retry via "Edit with AI" later.
**Why not `write_file`?** The `ContextFileInterceptor` blocks predefined file writes from chat by design. Bypassing it would create a security hole. Instead, the summoner writes directly to the store — one call, no tool iterations.
---
## 8. Skills -- 5-Tier Hierarchy
Skills are loaded from multiple directories with a priority ordering. Higher-tier skills override lower-tier skills with the same name.
```mermaid
flowchart TD
T1["Tier 1 (highest): Workspace skills
workspace/skills/name/SKILL.md"] --> T2
T2["Tier 2: Project agent skills
workspace/.agents/skills/"] --> T3
T3["Tier 3: Personal agent skills
~/.agents/skills/"] --> T4
T4["Tier 4: Global/managed skills
~/.goclaw/skills/"] --> T5
T5["Tier 5 (lowest): Builtin skills
(bundled with binary)"]
style T1 fill:#e1f5fe
style T5 fill:#fff3e0
```
Each skill directory contains a `SKILL.md` file with YAML/JSON frontmatter (`name`, `description`). The `{baseDir}` placeholder in SKILL.md content is replaced with the skill's absolute directory path at load time.
---
## 9. Skills -- Inline vs Search Mode
The system dynamically decides whether to embed skill summaries directly in the prompt (inline mode) or instruct the agent to use the `skill_search` tool (search mode).
```mermaid
flowchart TD
COUNT["Count filtered skills
Estimate tokens = sum(chars of name+desc) / 4"] --> CHECK{"skills <= 20
AND tokens <= 3500?"}
CHECK -->|Yes| INLINE["INLINE MODE
BuildSummary() produces XML
Agent reads available_skills directly"]
CHECK -->|No| SEARCH["SEARCH MODE
Prompt instructs agent to use skill_search
BM25 ranking returns top 5"]
```
This decision is re-evaluated each time the system prompt is built, so newly hot-reloaded skills are immediately reflected.
---
## 10. Skills -- BM25 Search
An in-memory BM25 index provides keyword-based skill search. The index is lazily rebuilt whenever the skill version changes.
**Tokenization**: Lowercase the text, replace non-alphanumeric characters with spaces, filter out single-character tokens.
**Scoring formula**: `IDF(t) x tf(t,d) x (k1 + 1) / (tf(t,d) + k1 x (1 - b + b x |d| / avgDL))`
| Parameter | Value |
|-----------|-------|
| k1 | 1.2 |
| b | 0.75 |
| Max results | 5 |
IDF is computed as: `log((N - df + 0.5) / (df + 0.5) + 1)`
---
## 11. Skills -- Embedding Search (Managed Mode)
In managed mode, skill search uses a hybrid approach combining BM25 and vector similarity.
```mermaid
flowchart TD
Q["Search query"] --> BM25["BM25 search
(in-memory index)"]
Q --> EMB["Generate query embedding"]
EMB --> VEC["Vector search
pgvector cosine distance
(embedding <=> operator)"]
BM25 --> MERGE["Weighted merge"]
VEC --> MERGE
MERGE --> RESULT["Final ranked results"]
```
| Component | Weight |
|-----------|--------|
| BM25 score | 0.3 |
| Vector similarity | 0.7 |
**Auto-backfill**: On startup, `BackfillSkillEmbeddings()` generates embeddings synchronously for any active skills that lack them.
---
## 12. Skills Grants & Visibility (Managed Mode)
In managed mode, skill access is controlled through a 3-tier visibility model with explicit agent and user grants.
```mermaid
flowchart TD
SKILL["Skill record"] --> VIS{"visibility?"}
VIS -->|public| ALL["Accessible to all agents and users"]
VIS -->|private| OWNER["Accessible only to owner
(owner_id = userID)"]
VIS -->|internal| GRANT{"Has explicit grant?"}
GRANT -->|skill_agent_grants| AGENT["Accessible to granted agent"]
GRANT -->|skill_user_grants| USER["Accessible to granted user"]
GRANT -->|No grant| DENIED["Not accessible"]
```
### Visibility Levels
| Visibility | Access Rule |
|------------|------------|
| `public` | All agents and users can discover and use the skill |
| `private` | Only the owner (`skills.owner_id = userID`) can access |
| `internal` | Requires an explicit agent grant or user grant |
### Grant Tables
| Table | Key | Extra |
|-------|-----|-------|
| `skill_agent_grants` | `(skill_id, agent_id)` | `pinned_version` for version pinning per agent, `granted_by` audit |
| `skill_user_grants` | `(skill_id, user_id)` | `granted_by` audit, ON CONFLICT DO NOTHING for idempotency |
**Resolution**: `ListAccessible(agentID, userID)` performs a DISTINCT join across `skills`, `skill_agent_grants`, and `skill_user_grants` with the visibility filter, returning only active skills the caller can access.
**Managed-mode Tier 4**: In managed mode, global skills (Tier 4 in the hierarchy) are loaded from the `skills` PostgreSQL table instead of the filesystem.
---
## 13. Hot-Reload
An fsnotify-based watcher monitors all skill directories for changes to SKILL.md files.
```mermaid
flowchart TD
S1["fsnotify detects SKILL.md change"] --> S2["Debounce 500ms"]
S2 --> S3["BumpVersion() sets version = timestamp"]
S3 --> S4["Next system prompt build detects
version change and reloads skills"]
```
New skill directories created inside a watched root are automatically added to the watch list. The debounce window (500ms) is shorter than the memory watcher (1500ms) because skill changes are lightweight.
---
## 14. Memory -- Indexing Pipeline
Memory documents are chunked, embedded, and stored for hybrid search.
```mermaid
flowchart TD
IN["Document changed or created"] --> READ["Read content"]
READ --> HASH["Compute SHA256 hash (first 16 bytes)"]
HASH --> CHECK{"Hash changed?"}
CHECK -->|No| SKIP["Skip -- content unchanged"]
CHECK -->|Yes| DEL["Delete old chunks for this document"]
DEL --> CHUNK["Split into chunks
(max 1000 chars, prefer paragraph breaks)"]
CHUNK --> EMBED{"EmbeddingProvider available?"}
EMBED -->|Yes| API["Batch embed all chunks"]
EMBED -->|No| SAVE
API --> SAVE["Store chunks + tsvector index
+ vector embeddings + metadata"]
```
### Chunking Rules
- Prefer splitting at blank lines (paragraph breaks) when the current chunk reaches half of `maxChunkLen`
- Force flush at `maxChunkLen` (1000 characters)
- Each chunk retains `StartLine` and `EndLine` from the source document
### Memory Paths
- `MEMORY.md` or `memory.md` at the workspace root
- `memory/*.md` (recursive, excluding `.git`, `node_modules`, etc.)
---
## 15. Hybrid Search
Combines full-text search and vector search with weighted merging.
```mermaid
flowchart TD
Q["Search(query)"] --> FTS["FTS Search
Standalone: SQLite FTS5 (BM25)
Managed: tsvector + plainto_tsquery"]
Q --> VEC["Vector Search
Standalone: cosine similarity
Managed: pgvector (cosine distance)"]
FTS --> MERGE["hybridMerge()"]
VEC --> MERGE
MERGE --> NORM["Normalize FTS scores to 0..1
Vector scores already in 0..1"]
NORM --> WEIGHT["Weighted sum
textWeight = 0.3
vectorWeight = 0.7"]
WEIGHT --> BOOST["Per-user scope: 1.2x boost
Dedup: user copy wins over global"]
BOOST --> RESULT["Sorted + filtered results"]
```
### Standalone vs Managed Comparison
| Aspect | Standalone | Managed |
|--------|-----------|---------|
| Storage | SQLite + FTS5 | PostgreSQL + tsvector + pgvector |
| FTS | `porter unicode61` tokenizer | `plainto_tsquery('simple')` |
| Vector | JSON array embedding | pgvector type |
| Scope | Global (single agent) | Per-agent + per-user |
| File watcher | fsnotify (1500ms debounce) | Not needed (DB-backed) |
When both FTS and vector search return results, scores are merged using the weighted sum. When only one channel returns results, its scores are used directly (weights normalized to 1.0).
---
## 16. Memory Flush -- Pre-Compaction
Before session history is compacted (summarized + truncated), the agent is given an opportunity to write durable memories to disk.
```mermaid
flowchart TD
CHECK{"totalTokens >= threshold?
(contextWindow - reserveFloor - softThreshold)
AND not flushed in this cycle?"} -->|Yes| FLUSH
CHECK -->|No| SKIP["Continue normal operation"]
FLUSH["Memory Flush"] --> S1["Step 1: Build flush prompt
asking to save memories to memory/YYYY-MM-DD.md"]
S1 --> S2["Step 2: Provide tools
(read_file, write_file, exec)"]
S2 --> S3["Step 3: Run LLM loop
(max 5 iterations, 90s timeout)"]
S3 --> S4["Step 4: Mark flush done
for this compaction cycle"]
S4 --> COMPACT["Proceed with compaction
(summarize + truncate history)"]
```
### Flush Defaults
| Parameter | Value |
|-----------|-------|
| softThresholdTokens | 4,000 |
| reserveTokensFloor | 20,000 |
| Max LLM iterations | 5 |
| Timeout | 90 seconds |
| Default prompt | "Store durable memories now." |
The flush is idempotent per compaction cycle -- it will not run again until the next compaction threshold is reached.
---
## File Reference
| File | Description |
|------|-------------|
| `internal/bootstrap/files.go` | Bootstrap file constants, loading, session filtering |
| `internal/bootstrap/truncate.go` | Truncation pipeline (head/tail split, budget clamping) |
| `internal/bootstrap/seed.go` | Standalone mode seeding (EnsureWorkspaceFiles) |
| `internal/bootstrap/seed_store.go` | Managed mode seeding (SeedToStore, SeedUserFiles) |
| `internal/bootstrap/load_store.go` | Load context files from DB (LoadFromStore) |
| `internal/bootstrap/templates/*.md` | Embedded template files |
| `internal/agent/systemprompt.go` | System prompt builder (BuildSystemPrompt, 17+ sections) |
| `internal/agent/systemprompt_sections.go` | Section renderers, virtual file handling (DELEGATION.md, TEAM.md) |
| `internal/agent/resolver.go` | Agent resolution, DELEGATION.md + TEAM.md injection |
| `internal/agent/loop_history.go` | Context file merging (base + per-user, base-only preserved) |
| `internal/agent/memoryflush.go` | Memory flush logic (shouldRunMemoryFlush, runMemoryFlush) |
| `internal/store/file/agents.go` | FileAgentStore -- filesystem + SQLite backend for standalone |
| `internal/http/summoner.go` | Agent summoning -- LLM-powered context file generation |
| `internal/skills/loader.go` | Skill loader (5-tier hierarchy, BuildSummary, filtering) |
| `internal/skills/search.go` | BM25 search index (tokenization, IDF scoring) |
| `internal/skills/watcher.go` | fsnotify watcher (500ms debounce, version bumping) |
| `internal/store/pg/skills.go` | Managed skill store (embedding search, backfill) |
| `internal/store/pg/skills_grants.go` | Skill grants (agent/user visibility, version pinning) |
| `internal/store/pg/memory_docs.go` | Memory document store (chunking, indexing, embedding) |
| `internal/store/pg/memory_search.go` | Hybrid search (FTS + vector merge, weighted scoring) |
---
## Cross-References
| Document | Relevant Content |
|----------|-----------------|
| [00-architecture-overview.md](./00-architecture-overview.md) | Startup sequence, managed mode wiring |
| [01-agent-loop.md](./01-agent-loop.md) | Agent loop calls BuildSystemPrompt, compaction flow |
| [03-tools-system.md](./03-tools-system.md) | ContextFileInterceptor routing read_file/write_file to DB |
| [06-store-data-model.md](./06-store-data-model.md) | memory_documents, memory_chunks tables |
---
# 08 - Scheduling, Cron & Heartbeat
Concurrency control and periodic task execution. The scheduler provides lane-based isolation and per-session serialization. Cron and heartbeat extend the agent loop with time-triggered behavior.
> **Managed mode**: Cron jobs and run logs are stored in the `cron_jobs` and `cron_run_logs` PostgreSQL tables. Cache invalidation propagates via the `cache:cron` event on the message bus. In standalone mode, cron state is persisted to JSON files.
### Responsibilities
- Scheduler: lane-based concurrency control, per-session message queue serialization
- Cron: three schedule kinds (at/every/cron), run logging, retry with exponential backoff
- Heartbeat: periodic agent wake-up, HEARTBEAT_OK detection, dedup within 24h
---
## 1. Scheduler Lanes
Named worker pools (semaphore-based) with configurable concurrency limits. Each lane processes requests independently. Unknown lane names fall back to the `main` lane.
```mermaid
flowchart TD
subgraph "Lane: main (concurrency = 2)"
M1["User chat 1"]
M2["User chat 2"]
end
subgraph "Lane: subagent (concurrency = 4)"
S1["Subagent 1"]
S2["Subagent 2"]
S3["Subagent 3"]
S4["Subagent 4"]
end
subgraph "Lane: delegate (concurrency = 100)"
D1["Delegation 1"]
D2["Delegation 2"]
end
subgraph "Lane: cron (concurrency = 1)"
C1["Cron job"]
end
REQ["Incoming request"] --> SCHED["Scheduler.Schedule(ctx, lane, req)"]
SCHED --> QUEUE["getOrCreateSession(sessionKey, lane)"]
QUEUE --> SQ["SessionQueue.Enqueue()"]
SQ --> LANE["Lane.Submit(fn)"]
```
### Lane Defaults
| Lane | Concurrency | Env Override | Purpose |
|------|:-----------:|-------------|---------|
| `main` | 2 | `GOCLAW_LANE_MAIN` | Primary user chat sessions |
| `subagent` | 4 | `GOCLAW_LANE_SUBAGENT` | Sub-agents spawned by the main agent |
| `delegate` | 100 | `GOCLAW_LANE_DELEGATE` | Agent delegation executions |
| `cron` | 1 | `GOCLAW_LANE_CRON` | Scheduled cron jobs (sequential to avoid conflicts) |
`GetOrCreate()` allows creating new lanes on demand with custom concurrency. All lane concurrency values are configurable via environment variables.
---
## 2. Session Queue
Each session key gets a dedicated queue that manages agent runs. The queue supports configurable concurrent runs per session.
### Concurrent Runs
| Context | `maxConcurrent` | Rationale |
|---------|:--------------:|-----------|
| DMs | 1 | Single-threaded per user (no interleaving) |
| Groups | 3 | Multiple users can get responses in parallel |
**Adaptive throttle**: When session history exceeds 60% of the context window, concurrency drops to 1 to prevent context window overflow.
### Queue Modes
| Mode | Behavior |
|------|----------|
| `queue` (default) | FIFO -- messages wait until a run slot is available |
| `followup` | Same as `queue` -- messages are queued as follow-ups |
| `interrupt` | Cancel the active run, drain the queue, start the new message immediately |
### Drop Policies
When the queue reaches capacity, one of two drop policies applies.
| Policy | When Queue Is Full | Error Returned |
|--------|-------------------|----------------|
| `old` (default) | Drop the oldest queued message, add the new one | `ErrQueueDropped` |
| `new` | Reject the incoming message | `ErrQueueFull` |
### Queue Config Defaults
| Parameter | Default | Description |
|-----------|---------|-------------|
| `mode` | `queue` | Queue mode (queue, followup, interrupt) |
| `cap` | 10 | Maximum messages in the queue |
| `drop` | `old` | Drop policy when full (old or new) |
| `debounce_ms` | 800 | Collapse rapid messages within this window |
---
## 3. /stop and /stopall Commands
Cancel commands for Telegram and other channels.
| Command | Behavior |
|---------|----------|
| `/stop` | Cancel the oldest running task; others keep going |
| `/stopall` | Cancel all running tasks + drain the queue |
### Implementation Details
- **Debouncer bypass**: `/stop` and `/stopall` are intercepted before the 800ms debouncer to avoid being merged with the next user message
- **Cancel mechanism**: `SessionQueue.Cancel()` exposes the `CancelFunc` from the scheduler. Context cancellation propagates to the agent loop
- **Empty outbound**: On cancel, an empty outbound message is published to trigger cleanup (stop typing indicator, clear reactions)
- **Trace finalization**: When `ctx.Err() != nil`, trace finalization falls back to `context.Background()` for the final DB write. Status is set to `"cancelled"`
- **Context survival**: Context values (traceID, collector) survive cancellation -- only the Done channel fires
---
## 4. Cron Lifecycle
Scheduled tasks that run agent turns automatically. The run loop checks every second for due jobs.
```mermaid
stateDiagram-v2
[*] --> Created: AddJob()
Created --> Scheduled: Compute nextRunAtMS
Scheduled --> DueCheck: runLoop (every 1s)
DueCheck --> Scheduled: Not yet due
DueCheck --> Executing: nextRunAtMS <= now
Executing --> Completed: Success
Executing --> Failed: Failure
Failed --> Retrying: retry < MaxRetries
Retrying --> Executing: Backoff delay
Failed --> ErrorLogged: Retries exhausted
Completed --> Scheduled: Compute next nextRunAtMS (every/cron)
Completed --> Deleted: deleteAfterRun (at jobs)
```
### Schedule Types
| Type | Parameter | Example |
|------|-----------|---------|
| `at` | `atMs` (epoch ms) | Reminder at 3PM tomorrow, auto-deleted after execution |
| `every` | `everyMs` | Every 30 minutes (1,800,000 ms) |
| `cron` | `expr` (5-field) | `"0 9 * * 1-5"` (9AM on weekdays) |
### Job States
Jobs can be `active` or `paused`. Paused jobs skip execution during the due check. Run results are logged to the `cron_run_logs` table. Cache invalidation propagates via the message bus.
### Retry -- Exponential Backoff with Jitter
| Parameter | Default |
|-----------|---------|
| MaxRetries | 3 |
| BaseDelay | 2 seconds |
| MaxDelay | 30 seconds |
**Formula**: `delay = min(base x 2^attempt, max) +/- 25% jitter`
---
## 5. Heartbeat -- 5 Steps
Periodically wakes the agent to check on events (calendar, inbox, alerts) and surfaces anything that needs attention.
```mermaid
flowchart TD
TICK["tick() -- every interval (default 30 min)"] --> S1{"Step 1:
Within Active Hours?"}
S1 -->|Outside hours| SKIP1["Skip"]
S1 -->|Within hours| S2{"Step 2:
HEARTBEAT.md exists
and has meaningful content?"}
S2 -->|No| SKIP2["Skip"]
S2 -->|Yes| S3["Step 3: runner()
Run agent with heartbeat prompt"]
S3 --> S4{"Step 4:
Reply contains HEARTBEAT_OK?"}
S4 -->|OK| LOG["Log debug, discard reply"]
S4 -->|Has content| S5{"Step 5:
Dedup -- same content
within 24h?"}
S5 -->|Duplicate| SKIP3["Skip"]
S5 -->|New| DELIVER["deliver() via resolveTarget()
then msgBus.PublishOutbound()"]
```
### Heartbeat Configuration
| Parameter | Default | Description |
|-----------|---------|-------------|
| Interval | 30 minutes | Time between heartbeat wakes |
| ActiveHours | (none) | Time window restriction, supports wrap-around midnight |
| Target | `"last"` | `"last"` (last-used channel), `"none"`, or explicit channel name |
| AckMaxChars | 300 | Content alongside HEARTBEAT_OK up to this length is still treated as OK |
### HEARTBEAT_OK Detection
Recognizes multiple formatting variants: `HEARTBEAT_OK`, `**HEARTBEAT_OK**`, `` `HEARTBEAT_OK` ``, `HEARTBEAT_OK`. Content accompanying the token is treated as an acknowledgment (OK) if it does not exceed `AckMaxChars`.
---
## File Reference
| File | Description |
|------|-------------|
| `internal/scheduler/lanes.go` | Lane and LaneManager (semaphore-based worker pools) |
| `internal/scheduler/queue.go` | SessionQueue, Scheduler, drop policies, debounce |
| `internal/cron/service.go` | Cron run loop, schedule parsing, job lifecycle |
| `internal/cron/retry.go` | Retry with exponential backoff + jitter |
| `internal/heartbeat/service.go` | Heartbeat loop, HEARTBEAT_OK detection, active hours |
| `internal/store/cron_store.go` | CronStore interface (jobs + run logs) |
| `internal/store/pg/cron.go` | PostgreSQL cron implementation |
---
## Cross-References
| Document | Relevant Content |
|----------|-----------------|
| [00-architecture-overview.md](./00-architecture-overview.md) | Scheduler lanes in startup sequence |
| [01-agent-loop.md](./01-agent-loop.md) | Agent loop triggered by scheduler |
| [06-store-data-model.md](./06-store-data-model.md) | cron_jobs, cron_run_logs tables |
---
# 09 - Security
Defense-in-depth with five independent layers from transport to isolation. Each layer operates independently -- even if one layer is bypassed, the remaining layers continue to protect the system.
> **Managed mode**: Adds AES-256-GCM encryption for secrets stored in PostgreSQL (LLM provider API keys, MCP server API keys, custom tool environment variables), plus agent-level access control via the 4-step `CanAccess` pipeline (see [06-store-data-model.md](./06-store-data-model.md)).
---
## 1. Five Defense Layers
```mermaid
flowchart TD
REQ["Request"] --> L1["Layer 1: Transport
CORS, message size limits, timing-safe auth"]
L1 --> L2["Layer 2: Input
Injection detection (6 patterns), message truncation"]
L2 --> L3["Layer 3: Tool
Shell deny patterns, path traversal, SSRF, exec approval"]
L3 --> L4["Layer 4: Output
Credential scrubbing, content wrapping"]
L4 --> L5["Layer 5: Isolation
Workspace isolation, Docker sandbox, read-only FS"]
```
### Layer 1: Transport Security
| Mechanism | Detail |
|-----------|--------|
| CORS (WebSocket) | `checkOrigin()` validates against `allowed_origins` (empty = allow all for backward compatibility) |
| WS message limit | `SetReadLimit(512KB)` -- gorilla auto-closes connection on exceed |
| HTTP body limit | `MaxBytesReader(1MB)` -- error returned before JSON decode |
| Token auth | `crypto/subtle.ConstantTimeCompare` (timing-safe) |
| Rate limiting | Token bucket per user/IP, configurable via `rate_limit_rpm` |
### Layer 2: Input -- Injection Detection
The input guard scans for 6 injection patterns.
| Pattern | Detection Target |
|---------|-----------------|
| `ignore_instructions` | "ignore all previous instructions" |
| `role_override` | "you are now...", "pretend you are..." |
| `system_tags` | ``, `[SYSTEM]`, `[INST]`, `<>` |
| `instruction_injection` | "new instructions:", "override:", "system prompt:" |
| `null_bytes` | Null characters `\x00` (obfuscation attempts) |
| `delimiter_escape` | "end of system", ``, `` |
**Configurable action** (`gateway.injection_action`):
| Value | Behavior |
|-------|----------|
| `"log"` | Log info level, continue processing |
| `"warn"` (default) | Log warning level, continue processing |
| `"block"` | Log warning, return error, stop processing |
| `"off"` | Disable detection entirely |
**Message truncation**: Messages exceeding `max_message_chars` (default 32K) are truncated (not rejected), and the LLM is notified of the truncation.
### Layer 3: Tool Security
**Shell deny patterns** -- 77+ patterns across multiple categories of blocked commands:
| Category | Examples |
|----------|----------|
| Destructive file ops | `rm -rf`, `del /f`, `rmdir /s` |
| Destructive disk ops | `mkfs`, `dd if=`, `> /dev/sd*` |
| System commands | `shutdown`, `reboot`, `poweroff` |
| Fork bombs | `:(){ ... };:` |
| Remote code execution | `curl \| sh`, `wget -O - \| sh` |
| Reverse shells | `/dev/tcp/`, `nc -e` |
| Eval injection | `eval $()`, `base64 -d \| sh` |
| Data exfiltration | `curl ... -d @/etc/passwd`, `exfil`, piping sensitive files to remote hosts |
| Privilege escalation | `sudo`, `su -`, `chmod 4755`, `chown root`, `setuid` |
| Dangerous path operations | Writes to `/etc/`, `/boot/`, `/sys/`, `/proc/` system directories |
**SSRF protection** -- 3-step validation:
```mermaid
flowchart TD
URL["URL to fetch"] --> S1["Step 1: Check blocked hostnames
localhost, *.local, *.internal,
metadata.google.internal"]
S1 --> S2["Step 2: Check private IP ranges
10.0.0.0/8, 172.16.0.0/12,
192.168.0.0/16, 127.0.0.0/8,
169.254.0.0/16, IPv6 loopback/link-local"]
S2 --> S3["Step 3: DNS Pinning
Resolve domain, check every resolved IP.
Also applied to redirect targets."]
S3 --> ALLOW["Allow request"]
```
**Path traversal**: `resolvePath()` applies `filepath.Clean()` then `HasPrefix()` to ensure all paths stay within the workspace. With `restrict = true`, any path outside the workspace is blocked.
**PathDenyable** -- An interface that lets filesystem tools reject specific path prefixes:
```go
type PathDenyable interface {
DenyPaths(...string)
}
```
All four filesystem tools (`read_file`, `write_file`, `list_files`, `edit`) implement `PathDenyable`. The agent loop calls `DenyPaths(".goclaw")` at startup to prevent agents from accessing internal data directories. `list_files` additionally filters denied directories from output entirely -- the agent does not see denied paths in directory listings.
### Layer 4: Output Security
| Mechanism | Detail |
|-----------|--------|
| Credential scrubbing | Regex detection of: OpenAI (`sk-...`), Anthropic (`sk-ant-...`), GitHub (`ghp_/gho_/ghu_/ghs_/ghr_`), AWS (`AKIA...`), generic key-value patterns. All replaced with `[REDACTED]`. |
| Web content wrapping | Fetched content wrapped in `<<>>` tags with security warning |
### Layer 5: Isolation
**Per-user workspace isolation** -- Two levels prevent cross-user file access:
| Level | Scope | Directory Pattern |
|-------|-------|------------------|
| Per-agent | Each agent gets its own base directory | `~/.goclaw/{agent-key}-workspace/` |
| Per-user | Each user gets a subdirectory within the agent workspace | `{agent-workspace}/user_{sanitized_id}/` |
The workspace is injected into tools via `WithToolWorkspace(ctx)` context injection. Tools read the workspace from context at execution time (fallback to the struct field for backward compatibility). User IDs are sanitized: anything outside `[a-zA-Z0-9_-]` becomes an underscore (`group:telegram:-1001234` → `group_telegram_-1001234`).
**Docker sandbox** -- Container-based isolation for shell command execution:
| Hardening | Configuration |
|-----------|---------------|
| Read-only root FS | `--read-only` |
| Drop all capabilities | `--cap-drop ALL` |
| No new privileges | `--security-opt no-new-privileges` |
| Memory limit | 512 MB |
| CPU limit | 1.0 |
| PID limit | Enabled |
| Network disabled | `--network none` |
| Tmpfs mounts | `/tmp`, `/var/tmp`, `/run` |
| Output limit | 1 MB |
| Timeout | 300 seconds |
---
## 2. Encryption (Managed Mode)
AES-256-GCM encryption for secrets stored in PostgreSQL. Key provided via `GOCLAW_ENCRYPTION_KEY` environment variable.
| What's Encrypted | Table | Column |
|-----------------|-------|--------|
| LLM provider API keys | `llm_providers` | `api_key` |
| MCP server API keys | `mcp_servers` | `api_key` |
| Custom tool env vars | `custom_tools` | `env` |
**Format**: `"aes-gcm:" + base64(12-byte nonce + ciphertext + GCM tag)`
Backward compatible: values without the `aes-gcm:` prefix are returned as plaintext (for migration from unencrypted data).
---
## 3. Rate Limiting -- Gateway + Tool
Protection at two levels: gateway-wide (per user/IP) and tool-level (per session).
```mermaid
flowchart TD
subgraph "Gateway Level"
GW_REQ["Request"] --> GW_CHECK{"rate_limit_rpm > 0?"}
GW_CHECK -->|No| GW_PASS["Allow all"]
GW_CHECK -->|Yes| GW_BUCKET{"Token bucket
has capacity?"}
GW_BUCKET -->|Available| GW_ALLOW["Allow + consume token"]
GW_BUCKET -->|Exhausted| GW_REJECT["WS: INVALID_REQUEST error
HTTP: 429 + Retry-After header"]
end
subgraph "Tool Level"
TL_REQ["Tool call"] --> TL_CHECK{"Entries in
last 1 hour?"}
TL_CHECK -->|">= maxPerHour"| TL_REJECT["Error: rate limit exceeded"]
TL_CHECK -->|"< maxPerHour"| TL_ALLOW["Record + allow"]
end
```
| Level | Algorithm | Key | Burst | Cleanup |
|-------|-----------|-----|:-----:|---------|
| Gateway | Token bucket | user/IP | 5 | Every 5 min (inactive > 10 min) |
| Tool | Sliding window | `agent:userID` | N/A | Manual `Cleanup()` |
Gateway rate limiting applies to both WebSocket (`chat.send`) and HTTP (`/v1/chat/completions`) chat endpoints. Config: `gateway.rate_limit_rpm` (0 = disabled, any positive value = enabled).
---
## 4. RBAC -- 3 Roles
Role-based access control for WebSocket RPC methods and HTTP API endpoints. Roles are hierarchical: higher levels include all permissions of lower levels.
```mermaid
flowchart LR
V["Viewer (level 1)
Read-only access"] --> O["Operator (level 2)
Read + Write"]
O --> A["Admin (level 3)
Full control"]
```
| Role | Key Permissions |
|------|----------------|
| Viewer | agents.list, config.get, sessions.list, health, status, skills.list |
| Operator | + chat.send, chat.abort, sessions.delete/reset, cron.*, skills.update |
| Admin | + config.apply/patch, agents.create/update/delete, channels.toggle, device.pair.approve/revoke |
### Access Check Flow
```mermaid
flowchart TD
REQ["Method call"] --> S1["Step 1: MethodRole(method)
Determine minimum required role"]
S1 --> S2{"Step 2: roleLevel(user) >= roleLevel(required)?"}
S2 -->|Yes| ALLOW["Allow"]
S2 -->|No| DENY["Deny"]
S2 --> S3["Step 3 (optional):
CanAccessWithScopes() for tokens
with narrow scope restrictions"]
```
Token-based role assignment happens during the WebSocket `connect` handshake. Scopes include: `operator.admin`, `operator.read`, `operator.write`, `operator.approvals`, `operator.pairing`.
---
## 5. Sandbox -- Container Lifecycle
Docker-based code isolation for shell command execution.
```mermaid
flowchart TD
REQ["Exec request"] --> CHECK{"ShouldSandbox?"}
CHECK -->|off| HOST["Execute on host
timeout: 60s"]
CHECK -->|non-main / all| SCOPE["ResolveScopeKey()"]
SCOPE --> GET["DockerManager.Get(scopeKey)"]
GET --> EXISTS{"Container exists?"}
EXISTS -->|Yes| REUSE["Reuse existing container"]
EXISTS -->|No| CREATE["docker run -d
+ security flags
+ resource limits
+ workspace mount"]
REUSE --> EXEC["docker exec sh -c [cmd]
timeout: 300s"]
CREATE --> EXEC
EXEC --> RESULT["ExecResult{ExitCode, Stdout, Stderr}"]
```
### Sandbox Modes
| Mode | Behavior |
|------|----------|
| `off` (default) | Execute directly on host |
| `non-main` | Sandbox all agents except main/default |
| `all` | Sandbox every agent |
### Container Scope
| Scope | Reuse Level | Scope Key |
|-------|-------------|-----------|
| `session` (default) | One container per session | sessionKey |
| `agent` | Shared across sessions for the same agent | `"agent:" + agentID` |
| `shared` | One container for all agents | `"shared"` |
### Workspace Access
| Mode | Mount |
|------|-------|
| `none` | No workspace access |
| `ro` | Read-only mount |
| `rw` | Read-write mount |
### Auto-Pruning
| Parameter | Default | Action |
|-----------|---------|--------|
| `idle_hours` | 24 | Remove containers idle for more than 24 hours |
| `max_age_days` | 7 | Remove containers older than 7 days |
| `prune_interval_min` | 5 | Check every 5 minutes |
### FsBridge -- File Operations in Sandbox
| Operation | Docker Command |
|-----------|---------------|
| ReadFile | `docker exec [id] cat -- [path]` |
| WriteFile | `docker exec -i [id] sh -c 'cat > [path]'` |
| ListDir | `docker exec [id] ls -la -- [path]` |
| Stat | `docker exec [id] stat -- [path]` |
---
## 6. Security Logging Convention
All security events use `slog.Warn` with a `security.*` prefix for consistent filtering and alerting.
| Event | Meaning |
|-------|---------|
| `security.injection_detected` | Prompt injection pattern detected |
| `security.injection_blocked` | Message blocked due to injection (when action = block) |
| `security.rate_limited` | Request rejected due to rate limit |
| `security.cors_rejected` | WebSocket connection rejected due to CORS policy |
| `security.message_truncated` | Message truncated because it exceeded the size limit |
Filter all security events by grepping for the `security.` prefix in log output.
---
## 7. Hook Recursion Prevention
The hook system (quality gates) can trigger infinite recursion: an agent evaluator delegates to a reviewer → delegation completes → fires quality gate → delegates to reviewer again → infinite loop.
A context flag `hooks.WithSkipHooks(ctx, true)` prevents this. Three injection points set the flag:
| Injection Point | Why |
|----------------|-----|
| Agent evaluator | Delegating to the reviewer for quality checks must not re-trigger gates |
| Evaluate-optimize loop | All internal generator/evaluator delegations skip gates |
| Agent eval callback (cmd layer) | When the hook engine itself triggers delegation |
`DelegateManager.Delegate()` checks `hooks.SkipHooksFromContext(ctx)` before applying quality gates. If the flag is set, gates are skipped entirely.
---
## 8. Delegation Security
Agent delegation uses directed permissions via the `agent_links` table.
| Control | Scope | Description |
|---------|-------|-------------|
| Directed links | A → B | A single row `(A→B, outbound)` means A can delegate to B, not the reverse |
| Per-user deny/allow | Per-link | `settings` JSONB on each link holds per-user restrictions (premium users only, blocked accounts) |
| Per-link concurrency | A → B | `agent_links.max_concurrent` limits simultaneous delegations from A to B |
| Per-agent load cap | B (all sources) | `other_config.max_delegation_load` limits total concurrent delegations targeting B |
When concurrency limits are hit, the error message is written for LLM reasoning: *"Agent at capacity (5/5). Try a different agent or handle it yourself."*
---
## File Reference
| File | Description |
|------|-------------|
| `internal/agent/input_guard.go` | Injection pattern detection (6 patterns) |
| `internal/tools/scrub.go` | Credential scrubbing (regex-based redaction) |
| `internal/tools/shell.go` | Shell deny patterns, command validation |
| `internal/tools/web_fetch.go` | Web content wrapping, SSRF protection |
| `internal/permissions/policy.go` | RBAC (3 roles, scope-based access) |
| `internal/gateway/ratelimit.go` | Gateway-level token bucket rate limiter |
| `internal/sandbox/` | Docker sandbox manager, FsBridge |
| `internal/crypto/aes.go` | AES-256-GCM encrypt/decrypt |
| `internal/tools/types.go` | PathDenyable interface definition |
| `internal/tools/filesystem.go` | Denied path checking (`checkDeniedPath` helper) |
| `internal/tools/filesystem_list.go` | Denied path support + directory filtering |
| `internal/hooks/context.go` | WithSkipHooks / SkipHooksFromContext (recursion prevention) |
| `internal/hooks/engine.go` | Hook engine, evaluator registry |
---
## Cross-References
| Document | Relevant Content |
|----------|-----------------|
| [03-tools-system.md](./03-tools-system.md) | Shell deny patterns, exec approval, PathDenyable, delegation system, quality gates |
| [04-gateway-protocol.md](./04-gateway-protocol.md) | WebSocket auth, RBAC, rate limiting |
| [06-store-data-model.md](./06-store-data-model.md) | API key encryption, agent access control pipeline, agent_links table |
| [07-bootstrap-skills-memory.md](./07-bootstrap-skills-memory.md) | Context file merging, virtual files |
| [08-scheduling-cron-heartbeat.md](./08-scheduling-cron-heartbeat.md) | Scheduler lanes, cron lifecycle |
| [10-tracing-observability.md](./10-tracing-observability.md) | Tracing and OTel export |
---
# 10 - Tracing & Observability
Records agent run activities asynchronously. Spans are buffered in memory and flushed to the TracingStore in batches, with optional export to external OpenTelemetry backends.
> **Managed mode only**: Tracing requires PostgreSQL. In standalone mode, `TracingStore` is nil and no traces are recorded. The `traces` and `spans` tables store all tracing data. Optional OTel export sends spans to external backends (Jaeger, Grafana Tempo, Datadog) in addition to PostgreSQL.
---
## 1. Collector -- Buffer-Flush Architecture
```mermaid
flowchart TD
EMIT["EmitSpan(span)"] --> BUF["spanCh
(buffered channel, cap = 1000)"]
BUF --> FLUSH["flushLoop() -- every 5s"]
FLUSH --> DRAIN["Drain all spans from channel"]
DRAIN --> BATCH["BatchCreateSpans() to PostgreSQL"]
DRAIN --> OTEL["OTelExporter.ExportSpans()
to OTLP backend (if configured)"]
DRAIN --> AGG["Update aggregates
for dirty traces"]
FULL{"Buffer full?"} -.->|"Drop + warning log"| BUF
```
### Trace Lifecycle
```mermaid
flowchart LR
CT["CreateTrace()
(synchronous, 1 per run)"] --> ES["EmitSpan()
(async, buffered)"]
ES --> FT["FinishTrace()
(status, error, output preview)"]
```
### Cancel Handling
When a run is cancelled via `/stop` or `/stopall`, the run context is cancelled but trace finalization still needs to persist. `FinishTrace()` detects `ctx.Err() != nil` and switches to `context.Background()` for the final database write. The trace status is set to `"cancelled"` instead of `"error"`.
Context values (traceID, collector) survive cancellation -- only `ctx.Done()` and `ctx.Err()` change. This allows trace finalization to find everything it needs with a fresh context for the DB call.
---
## 2. Span Types & Hierarchy
| Type | Description | OTel Kind |
|------|-------------|-----------|
| `llm_call` | LLM provider call | Client |
| `tool_call` | Tool execution | Internal |
| `agent` | Root agent span (parents all child spans) | Internal |
```mermaid
flowchart TD
AGENT["Agent Span (root)
parents all child spans"] --> LLM1["LLM Call Span 1
(model, tokens, finish reason)"]
AGENT --> TOOL1["Tool Span: exec
(tool_name, duration)"]
AGENT --> LLM2["LLM Call Span 2"]
AGENT --> TOOL2["Tool Span: read_file"]
AGENT --> LLM3["LLM Call Span 3"]
```
### Token Aggregation
Token counts are aggregated **only from `llm_call` spans** (not `agent` spans) to avoid double-counting. The `BatchUpdateTraceAggregates()` method sums `input_tokens` and `output_tokens` from spans where `span_type = 'llm_call'` and writes the totals to the parent trace record.
---
## 3. Verbose Mode
| Mode | InputPreview | OutputPreview |
|------|:---:|:---:|
| Normal | Not recorded | 500 characters max |
| Verbose (`GOCLAW_TRACE_VERBOSE=1`) | Up to 50KB | 500 characters max |
Verbose mode is useful for debugging LLM conversations. Full input messages (including system prompt, history, and tool results) are serialized as JSON and stored in the span's `InputPreview` field, truncated at 50,000 characters.
---
## 4. OTel Export
Optional OpenTelemetry OTLP exporter that sends spans to external observability backends.
```mermaid
flowchart TD
COLLECTOR["Collector flush cycle"] --> CHECK{"SpanExporter set?"}
CHECK -->|No| PG_ONLY["Write to PostgreSQL only"]
CHECK -->|Yes| BOTH["Write to PostgreSQL
+ ExportSpans() to OTLP backend"]
BOTH --> BACKEND["Jaeger / Tempo / Datadog"]
```
### OTel Configuration
| Parameter | Description |
|-----------|-------------|
| `endpoint` | OTLP endpoint (e.g., `localhost:4317` for gRPC, `localhost:4318` for HTTP) |
| `protocol` | `grpc` (default) or `http` |
| `insecure` | Skip TLS for local development |
| `service_name` | OTel service name (default: `goclaw-gateway`) |
| `headers` | Extra headers (auth tokens, etc.) |
### Batch Processing
| Parameter | Value |
|-----------|-------|
| Max batch size | 100 spans |
| Batch timeout | 5 seconds |
The exporter lives in a separate sub-package (`internal/tracing/otelexport/`) so its gRPC and protobuf dependencies are isolated. Commenting out the import and wiring removes approximately 15-20MB from the binary. The exporter is attached to the Collector via `SetExporter()`.
---
## 5. Trace HTTP API (Managed Mode)
| Method | Path | Description |
|--------|------|-------------|
| GET | `/v1/traces` | List traces with pagination and filters |
| GET | `/v1/traces/{id}` | Get trace details with all spans |
### Query Filters
| Parameter | Type | Description |
|-----------|------|-------------|
| `agent_id` | UUID | Filter by agent |
| `user_id` | string | Filter by user |
| `status` | string | Filter by status (running, success, error, cancelled) |
| `from` / `to` | timestamp | Date range filter |
| `limit` | int | Page size (default 50) |
| `offset` | int | Pagination offset |
---
## 6. Delegation History (Managed Mode)
Delegation history records are stored in the `delegation_history` table and exposed alongside traces for cross-referencing agent interactions.
| Channel | Endpoint | Details |
|---------|----------|---------|
| WebSocket RPC | `delegations.list` / `delegations.get` | Results truncated (500 runes for list, 8000 for detail) |
| HTTP API | `GET /v1/delegations` / `GET /v1/delegations/{id}` | Full records |
| Agent tool | `delegate(action="history")` | Agent self-checking past delegations |
Delegation history is automatically recorded by `DelegateManager.saveDelegationHistory()` for every delegation (sync/async). Each record includes source agent, target agent, input, result, duration, and status.
---
## File Reference
| File | Description |
|------|-------------|
| `internal/tracing/collector.go` | Collector buffer-flush, EmitSpan, FinishTrace |
| `internal/tracing/context.go` | Trace context propagation (TraceID, ParentSpanID) |
| `internal/tracing/otelexport/exporter.go` | OTel OTLP exporter (gRPC + HTTP) |
| `internal/store/tracing_store.go` | TracingStore interface |
| `internal/store/pg/tracing.go` | PostgreSQL trace/span persistence + aggregation |
| `internal/http/traces.go` | Trace HTTP API handler (GET /v1/traces) |
| `internal/agent/loop_tracing.go` | Span emission from agent loop (LLM, tool, agent spans) |
| `internal/http/delegations.go` | Delegation history HTTP API handler |
| `internal/gateway/methods/delegations.go` | Delegation history RPC handlers |
---
## Cross-References
| Document | Relevant Content |
|----------|-----------------|
| [01-agent-loop.md](./01-agent-loop.md) | Span emission during agent execution, cancel handling |
| [03-tools-system.md](./03-tools-system.md) | Delegation system, delegation history via agent tool |
| [06-store-data-model.md](./06-store-data-model.md) | traces/spans tables schema, delegation_history table |
| [08-scheduling-cron-heartbeat.md](./08-scheduling-cron-heartbeat.md) | /stop and /stopall commands |
| [09-security.md](./09-security.md) | Rate limiting, RBAC access control |
---
# Web Dashboard
The GoClaw Web Dashboard is a React 19 single-page application (SPA) built with Vite 6, TypeScript, Tailwind CSS 4, and Radix UI. It connects to the GoClaw gateway via WebSocket and provides a full management interface for agents, teams, tools, providers, and observability.
---
## 1. Core
### Chat (`/chat`)
Interactive chat interface for direct agent conversation.
- **Agent selector** — dropdown to switch active agent
- **Session list** — shows message count and timestamp per session
- **New Chat** button — starts a fresh session
- Message input with send action
---
## 2. Management
### Agents (`/agents`)
Card grid of all registered AI agents.
Each card shows: name, slug, provider/model, description, status badge (`active`/`inactive`), access type (`predefined` / `open`), and context window size.
Actions: **Create Agent**, search by name/slug, edit, delete.
### Agent Teams (`/teams`)
Manages multi-agent team configurations.
Each team card shows: team name, status, lead agent. Actions: **Create Team**, search, edit, delete.
### Sessions (`/sessions`)
Lists all conversation sessions across agents and channels. Supports filtering and deletion.
### Channels (`/channels`)
Configuration for external messaging channels (Telegram, Slack, etc.) connected to the gateway.
### Skills (`/skills`)
Manages agent skill packages (ZIP uploads). Actions: **Upload**, **Refresh**, search by name.
### Built-in Tools (`/builtin-tools`)
26 built-in tools across 13 categories. Each tool can be individually enabled or disabled.
| Category | Tools |
|---|---|
| Filesystem | `edit`, `list_files`, `read_file`, `write_file` |
| Runtime | `exec` |
| Web | `web_fetch`, `web_search` |
| Memory | `memory_get`, `memory_search` |
| (+ 9 more categories) | — |
---
## 3. Monitoring
### Traces (`/traces`)
Table of LLM call traces.
| Column | Description |
|---|---|
| Name | Trace / run label |
| Status | `completed`, `error`, etc. |
| Duration | Wall-clock time |
| Tokens | Input / output / cached token counts |
| Spans | Number of child spans |
| Time | Timestamp |
Filter by agent ID. **Refresh** button for manual reload.
### Delegations (`/delegations`)
Tracks inter-agent delegation events — which agent delegated a task to which sub-agent, with status and timing.
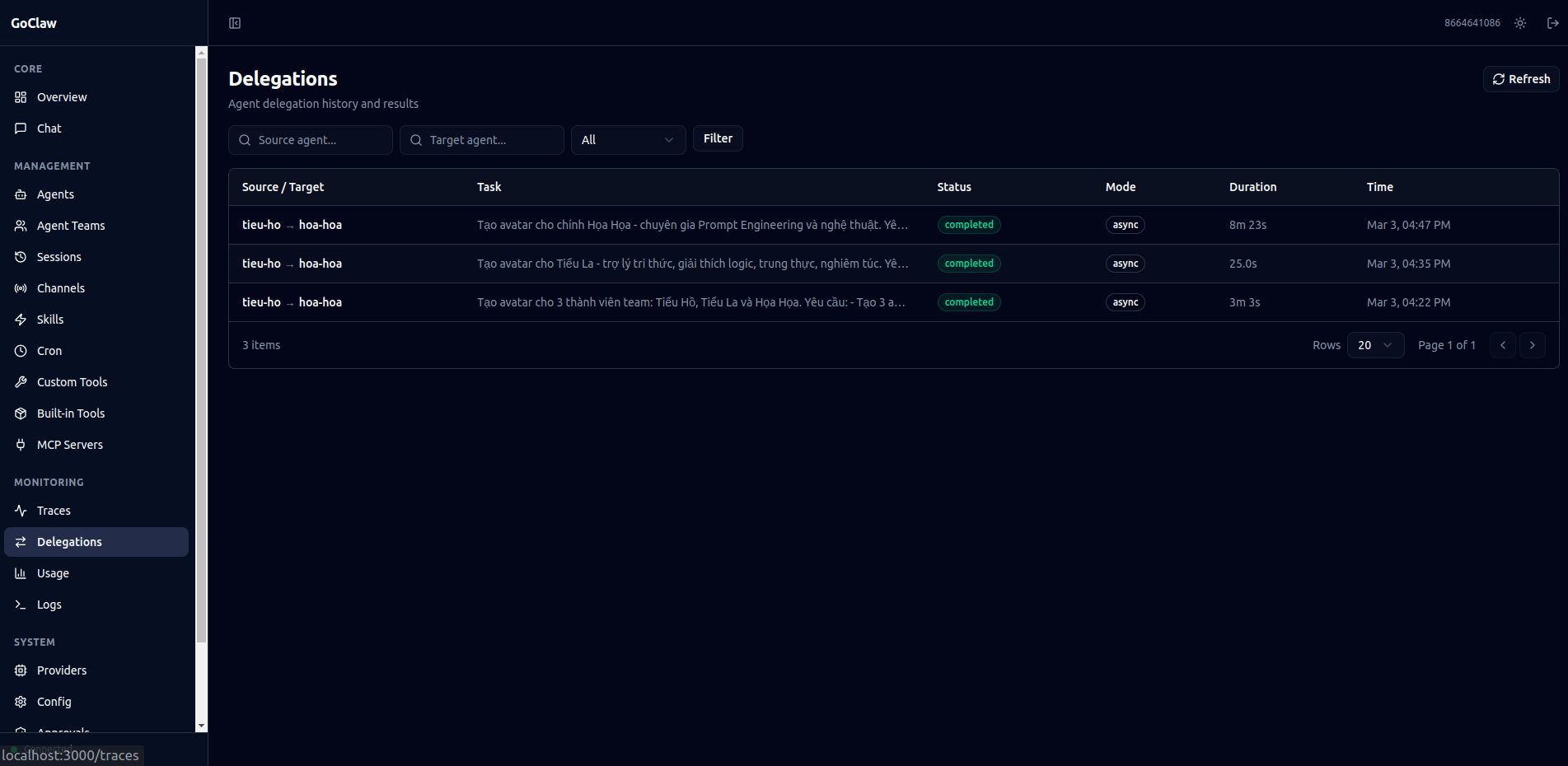
---
## 4. System
### Providers (`/providers`)
LLM provider management table.
| Column | Description |
|---|---|
| Name | Provider label |
| Type | `dashscope`, `bailian`, `gemini`, `openrouter`, `openai_compat` |
| API Base URL | Endpoint |
| API Key | Masked |
| Status | `Enabled` / `Disabled` |
Actions: **Add Provider**, **Refresh**, edit, delete per row.
### Config (`/config`)
Gateway configuration editor with two modes: **UI form** and **Raw Editor**.
Sections:
- **Gateway** — host, port, token, owner IDs, allowed origins, rate limit (RPM), max message chars, inbound debounce, injection action
- **LLM Providers** — inline provider list
- **Agent Defaults** — default model settings
> A yellow info banner reminds that environment variables take precedence over UI-set values and that secrets should be configured via env, not stored in the config file.
---
## 5. Accessing the Dashboard
The dashboard is bundled with GoClaw and automatically available when the gateway starts. No separate setup required.
- **URL**: `http://localhost:3000` (default)
- **Connection**: Connects to the gateway via WebSocket automatically
- See [Getting Started](#getting-started) for installation and startup instructions
---
# API Reference
## HTTP Endpoints
| Method | Path | Description |
|--------|------|-------------|
| GET | `/health` | Health check |
| GET | `/ws` | WebSocket upgrade |
| POST | `/v1/chat/completions` | OpenAI-compatible chat API |
| POST | `/v1/responses` | Responses protocol |
| POST | `/v1/tools/invoke` | Tool invocation |
| GET/POST | `/v1/agents/*` | Agent management (managed mode) |
| GET/POST | `/v1/skills/*` | Skills management (managed mode) |
| GET/POST/PUT/DELETE | `/v1/tools/custom/*` | Custom tool CRUD (managed mode) |
| GET/POST/PUT/DELETE | `/v1/mcp/*` | MCP server + grants management (managed mode) |
| GET | `/v1/traces/*` | Trace viewer (managed mode) |
## Custom Tools (Managed Mode)
Define shell-based tools at runtime via HTTP API — no recompile or restart needed. The LLM can invoke custom tools identically to built-in tools.
**How it works:**
1. Admin creates a tool via `POST /v1/tools/custom` with a shell command template
2. LLM generates a tool call with the custom tool name
3. GoClaw renders the command template with shell-escaped arguments, checks deny patterns, and executes with timeout
**Capabilities:**
- **Scope** — Global (all agents) or per-agent (`agent_id` field)
- **Parameters** — JSON Schema definition for LLM arguments
- **Security** — All arguments auto shell-escaped, deny pattern filtering (blocks `curl|sh`, reverse shells, etc.), configurable timeout (default 60s)
- **Encrypted env vars** — Environment variables stored with AES-256-GCM encryption in the database
- **Cache invalidation** — Mutations broadcast events for hot-reload without restart
**API:**
| Method | Path | Description |
|---|---|---|
| GET | `/v1/tools/custom` | List tools (filter by `?agent_id=`) |
| POST | `/v1/tools/custom` | Create a custom tool |
| GET | `/v1/tools/custom/{id}` | Get tool details |
| PUT | `/v1/tools/custom/{id}` | Update a tool (JSON patch) |
| DELETE | `/v1/tools/custom/{id}` | Delete a tool |
**Example — create a tool that checks DNS records:**
```json
{
"name": "dns_lookup",
"description": "Look up DNS records for a domain",
"parameters": {
"type": "object",
"properties": {
"domain": { "type": "string", "description": "Domain name to look up" },
"record_type": { "type": "string", "enum": ["A", "AAAA", "MX", "CNAME", "TXT"] }
},
"required": ["domain"]
},
"command": "dig +short {{.record_type}} {{.domain}}",
"timeout_seconds": 10,
"enabled": true
}
```
## MCP Integration
Connect external [Model Context Protocol](https://modelcontextprotocol.io) servers to extend agent capabilities. MCP tools are registered transparently into GoClaw's tool registry and invoked like any built-in tool.
**Supported transports:** `stdio`, `sse`, `streamable-http`
**Standalone mode** — configure in `config.json`:
```json
{
"mcp": {
"servers": {
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "/workspace"]
},
"remote-tools": {
"transport": "streamable-http",
"url": "https://mcp.example.com/tools"
}
}
}
}
```
**Managed mode** — full CRUD via HTTP API with per-agent and per-user access grants:
| Method | Path | Description |
|---|---|---|
| GET | `/v1/mcp/servers` | List registered MCP servers |
| POST | `/v1/mcp/servers` | Register a new MCP server |
| GET | `/v1/mcp/servers/{id}` | Get server details |
| PUT | `/v1/mcp/servers/{id}` | Update server config |
| DELETE | `/v1/mcp/servers/{id}` | Remove MCP server |
| POST | `/v1/mcp/servers/{id}/grants/agent` | Grant access to an agent |
| DELETE | `/v1/mcp/servers/{id}/grants/agent/{agentID}` | Revoke agent access |
| GET | `/v1/mcp/grants/agent/{agentID}` | List agent's MCP grants |
| POST | `/v1/mcp/servers/{id}/grants/user` | Grant access to a user |
| DELETE | `/v1/mcp/servers/{id}/grants/user/{userID}` | Revoke user access |
| POST | `/v1/mcp/requests` | Request access (user self-service) |
| GET | `/v1/mcp/requests` | List pending access requests |
| POST | `/v1/mcp/requests/{id}/review` | Approve or reject a request |
**Features:**
- **Multi-server** — Connect multiple MCP servers simultaneously
- **Tool name prefixing** — Optional `{prefix}__{toolName}` to avoid collisions
- **Per-agent grants** — Control which agents can access which MCP servers, with tool allow/deny lists
- **Per-user grants** — Fine-grained user-level access control
- **Access requests** — Users can request access; admins approve or reject
---
# WebSocket Protocol (v3)
Frame types: `req` (client request), `res` (server response), `event` (server push).
## Authentication
The first request must be a `connect` handshake. Authentication supports three paths:
```json
// Path 1: Token-based (admin role)
{"type": "req", "id": 1, "method": "connect", "params": {"token": "your-gateway-token", "user_id": "alice"}}
// Path 2: Browser pairing reconnect (operator role)
{"type": "req", "id": 1, "method": "connect", "params": {"sender_id": "previously-paired-id", "user_id": "alice"}}
// Path 3: No token — initiates browser pairing flow (returns pairing code)
{"type": "req", "id": 1, "method": "connect", "params": {"user_id": "alice"}}
```
## Methods
| Method | Description |
|--------|-------------|
| `connect` | Authentication handshake (must be first request) |
| `health` | Server health check |
| `status` | Server status and metadata |
| `chat.send` | Send a message to an agent |
| `chat.history` | Retrieve session history |
| `chat.abort` | Abort a running agent request |
| `agent` | Get agent info |
| `sessions.list` | List active sessions |
| `sessions.delete` | Delete a session |
| `sessions.patch` | Update session metadata |
| `skills.list` | List available skills |
| `cron.list` | List scheduled jobs |
| `cron.create` | Create a cron job |
| `cron.delete` | Delete a cron job |
| `cron.toggle` | Enable/disable a cron job |
| `models.list` | List available AI models |
| `browser.pairing.status` | Poll pairing approval status |
| `device.pair.request` | Request device pairing |
| `device.pair.approve` | Approve a pairing code |
| `device.pair.list` | List pending and approved pairings |
| `device.pair.revoke` | Revoke a pairing |
## Events (server push)
| Event | Description |
|-------|-------------|
| `chunk` | Streaming token from LLM (payload: `{content}`) |
| `tool.call` | Agent invoking a tool (payload: `{name, id}`) |
| `tool.result` | Tool execution result |
| `run.started` | Agent started processing |
| `run.completed` | Agent finished processing |
| `shutdown` | Server shutting down |
## Frame Format
### Request (client to server)
```json
{
"type": "req",
"id": "unique-request-id",
"method": "chat.send",
"params": { ... }
}
```
### Response (server to client)
```json
{
"type": "res",
"id": "matching-request-id",
"ok": true,
"payload": { ... }
}
```
### Error Response
```json
{
"type": "res",
"id": "matching-request-id",
"ok": false,
"error": {
"code": "error_code",
"message": "Human-readable error message"
}
}
```
### Event (server push)
```json
{
"type": "event",
"event": "chunk",
"payload": { "content": "streaming text..." }
}
```
---